Linda Van Guilder
vanguill@gusun.georgetown.edu
Handout for LING361,
Fall 1995
Georgetown University
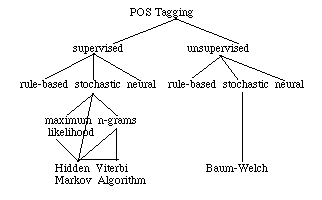
There are many approaches to automated part of speech tagging. This handout is intended to serve as a brief introduction to the types of tagging schemes commonly used today, although no specific system will be discussed. For each issue addressed, pointers to primary literature are provided.
The primary argument for using a fully automated approach to POS tagging is that it is extremely portable. It is known that automatic POS taggers tend to perform best when both trained and tested on the same genre of text. The unfortunate reality is that pre-tagged corpora are not readily available for the many languages and genres which one might wish to tag. Full automation of the tagging process addresses the need to accurately tag previously untagged genres and languages in light of the fact that hand tagging of training data is a costly and time-consuming process. There are, however, drawbacks to fully automating the POS tagging process. The word clusterings which tend to result from these methods are very coarse, i.e., one loses the fine distinctions found in the carefully designed tag sets used in the supervised methods.
The following table outlines the differences between these two approaches.
| SUPERVISED | UNSUPERVISED |
|---|---|
| selection of tagset/tagged corpus | induction of tagset using untagged training data |
| creation of dictionaries using tagged corpus | induction of dictionary using training data |
| calculation of disambiguation tools. may include: | induction of disambiguation tools. may include: |
| word frequencies | word frequencies |
| affix frequencies | affix frequencies |
| tag sequence probabilities | tag sequence probabilities |
| "formulaic" expressions | |
| tagging of test data using dictionary information | tagging of test data using induced dictionaries |
| disambiguation using statistical, hybrid or rule based approaches | disambiguation using statistical, hybrid or rule based approaches |
| calculation of tagger accuracy | calculation of tagger accuracy |
For a more thorough discussion of the supervised vs. unsupervised training, see: Brill & Marcus (1993) or Brill (1995), Schütze (1993).
det - X - n = X/adj
In addition to contextual information, many taggers use morphological information to aid in the disambiguation process. One such rule might be: if an ambiguous/unknown word ends in an -ing and is preceded by a verb, label it a verb (depending on your theory of grammar, of course).
Some systems go beyond using contextual and morphological information by including rules pertaining to such factors as capitalization and punctuation. Information of this type is of greater or lesser value depending on the language being tagged. In German for example, information about capitalization proves extremely useful in the tagging of unknown nouns.
Rule based taggers most commonly require supervised training; but, very recently there has been a great deal of interest in automatic induction of rules. One approach to automatic rule induction is to run an untagged text through a tagger and see how it performs. A human then goes through the output of this first phase and corrects any erroneously tagged words The properly tagged text is then submitted to the tagger, which learns correction rules by comparing the two sets of data. Several iterations of this process are sometimes necessary.
For further information on rule-based taggers, see: Brill (1995), Brill (1992), Greene & Rubin (1971), Tapanainen & Voutilainen (1994).
The simplest stochastic taggers disambiguate words based solely on the probability that a word occurs with a particular tag. In other words, the tag encountered most frequently in the training set is the one assigned to an ambiguous instance of that word. The problem with this approach is that while it may yield a valid tag for a given word, at can also yield inadmissible sequences of tags.
An alternative to the word frequency approach is to calculate the probability of a given sequence of tags occurring. This is sometimes referred to as the n-gram approach, referring to the fact that the best tag for a given word is determined by the probability that it occurs with the n previous tags. The most common algorithm for implementing an n-gram approach is known as the Viterbi Algorithm, a search algorithm which avoids the polynomial expansion of a breadth first search by "trimming" the search tree at each level using the best N Maximum Likelihood Estimates (where n represents the number of tags of the following word).
The next level of complexity that can be introduced into a stochastic tagger combines the previous two approaches, using both tag sequence probabilities and word frequency measurements. This is known as a Hidden Markov Model. The assumptions underlying this model are the following:
Each hidden tag state produces a word in the sentence. Each word is:
Hidden Markov Model taggers and visible Markov Model taggers may be implemented using the Viterbi algorithm, and are among the most efficient of the tagging methods discussed here. HMM's cannot, however, be used in an automated tagging schema, since they rely critically upon the calculation of statistics on output sequences (tagstates). The solution to the problem of being unable to automatically train HMMs is to employ the Baum-Welch Algorithm, also known as the Forward-Backward Algorithm. This algorithm uses word rather than tag information to iteratively construct a sequences to improve the probability of the training data.
For a general discussion of stochastic approaches, see: Allen
(1995), DeRose
(1988), Merialdo
(1994).
For a discussion of the Viterbi Algorithm, see: Brill
& Marcus (1993).
For a discussion of Hidden Markov Models. see: Baum
(1972), Kupiec
(1992), Rabiner
(1989).
For a discussion of using morphology in stochastic models: Maltese
& Mancini (1989).
For general discussion: Weischedel
et al. (1993).
In order to create a matrix of transitional probabilities, it is necessary to begin with a tagged corpus upon which to base the estimates of those probabilities. For the purpose of exposition, we will consider how to go about determining those values using a bigram model, i.e. we will base our estimates on the immediate context of a words and will not consider any context further than one word away.
The first step in this process is to determine the probability. of each category's occurrence. This is a matter of straightforward probability calculation. In order to determine the probability of a noun occurring in a given corpus, we divide the total number of nouns by the total number of words. So, if we had a hundred word corpus and 20 of those words were nouns, the estimated probability of a noun occurring would be 20/100 or. 20. Likewise, if there were thirty determiners in the same corpus, the probability of a determiner occurring would be .30.
Next, we face the problem of determining transitional probabilities for sequences of words, which boils down to calculating the number of times that the event occurs given the occurrence of another event. This is known as conditional probability, for which the generic formula is:
PROB(e | e') = PROB(e & e') / PROB(e')
That formula reads: the probability of an event e occurring given the occurrence of another event e' is equal to the probability of both events occurring at once divided by the probability of the occurrence of e'.
We can put this formula to work for us in determining the transitional probabilities in the following way: Suppose that we wish to determine the probability of a noun following a determiner. We plug these categories into the probability formula:
PROB(noun | det) = PROB(det & noun) / PROB(det)
Again, this reads: the probability of a noun occurring given the occurrence of a determiner is equal to the probability of a determiner and a noun occurring together, divided by the probability of a determiner occurring. In practice, a variation of this formula is used wherein category frequencies are used rather than category probabilities. So the formula, adapted from Allen (1995:198), turns out to be:
PROB(Cat i = noun | Cat i-1 = det) ![]() Count(det at position i-1 and noun
at i) / Count(det at position i-1)
Count(det at position i-1 and noun
at i) / Count(det at position i-1)
This, then, is the formula for determining bigram transitional probabilities. The number of probabilities for a corpus equals the number of tags in the tagset squared. The start and end categories are always included in the calculation of N squared.
There is, however, a flaw in the formula for conditional probabilities, at least insofar as using it to determine transitional probabilities is concerned. The trouble is that words which occur with great frequency, such as nouns, get favored too heavily during the disambiguation process, resulting in a decrease in the precision of the system. The problem is that the frequency of the category at i-1 was never taken into account. The solution is to slightly modify that equation to include the frequency of the context word:
PROB(Cat i = noun | Cat i-1 = det) ![]() Count(det at position i-1 and noun
at i) / (Count(det at position i-1) * Count(noun at position i))
Count(det at position i-1 and noun
at i) / (Count(det at position i-1) * Count(noun at position i))
In this new formulation, the denominator is the product of the frequencies of the words in the bigram, rather than just the frequency of the context word.
The final step in the basic probabilistic disambiguation process is to use the transitional probabilities just computed to determine the optimal path through the search space ranging from one unambiguous tag to the next. In other words, it is necessary to implement some kind of search algorithm which will allow the calculations just made to be of some use in the disambiguation process. In the algorithms we have considered here, the products of the transitional probabilities at each node were used. The principle which allows this type of formula to be used is known as the Markov assumption, which takes for granted that the probability of a particular category occurring depends solely on the category immediately preceding it. Algorithms which rely on the Markov assumption to determine the optimal path are known as Markov models. Note that they are not, in the strictest definition of the term, to be confused with Hidden Markov models. "A Markov model is hidden when you cannot determine the state sequence it has passed through on the basis of the outputs you observed." (Manning, Chris, Corpora List correspondence). The efficiency of a Markov model is best exploited when used in conjunction with some form of a best first search algorithm so as to avoid the polynomial time problem, as will be illustrated below.
For an introduction to basic probability theory, see: Allen (1995) or Larsen & Marx (1986).
| The | AT | ||
| man | NN | VB | |
| still | NN | VB | RB |
| saw | NN | VBD | |
| her | PPO | PP$ |
In order to determine the optimal tagset for this sentence we will also need the table of transitional probabilities given in the same paper:
| NN | PPO | PP$ | RB | VB | VBD | . | |
|---|---|---|---|---|---|---|---|
| AT | 186 | 0 | 0 | 8 | 1 | 8 | 9 |
| NN | 40 | 1 | 3 | 40 | 9 | 66 | 186 |
| PPO | 7 | 3 | 16 | 164 | 109 | 16 | 313 |
| PP$ | 176 | 0 | 0 | 5 | 1 | 1 | 2 |
| RB | 5 | 3 | 16 | 164 | 109 | 16 | 313 |
| VB | 22 | 694 | 146 | 98 | 9 | 1 | 59 |
| VBD | 11 | 584 | 143 | 160 | 2 | 1 | 91 |
The search begins with the unambiguous article. Expanding the tree to include the next states, the possible paths become (AT-NN) and (AT-VB). We now look up the transitional probabilities for these two paths in table 3 and find that p(AT-NN)=186 and p(AT-VB)=1. Since, at this point, there is only one path to each of the tags for the word 'man' we keep both of these paths and go on to expand the tree again. This time there are nine paths under consideration. The probability for each of these paths is obtained by multiplying the probability of the last transition by the probability for the whole path to this point. The best path to each unique tag will be maintained, in this case p(AT-NN-NN)=744, p(AT-NN-VB)=1674 and p(AT-NN-RB)=7440. At this point, the basic functionality of the algorithm has been explained.
Using an algorithm that runs in near-linear time makes having a syntactic tagger as the front end for a natural language system a much more attractive and viable prospect than in the past. The system is also desirable on the basis of its accuracy, which was found to be 96% on the Brown Corpus without the advantage of pretagging idioms, and was predicted to be 99% with an idiomatic dictionary.
Allen, James. 1995. Natural Language Understanding. Redwood City, CA: Benjamin Cummings.
Baum, L. 1972. An inequality and associated maximization technique in statistical estimation for probabilistic functions of a Markov process. Inequalities 3:1-8.
Brill, Eric. 1992. A simple rule-based part of speech tagger. Proceedings of the Third Annual Conference on Applied Natural Language Processing, ACL.
Brill, Eric. 1995. Unsupervised learning of disambiguation rules for part of speech tagging.
Brill, Eric & Marcus, M. 1993. Tagging an unfamiliar text with minimal human supervision. ARPA Technical Report.
Dermatas, Evangelos & Kokkinakis, George. 1995. Automatic stochastic tagging of natural language texts. Computational Linguistics 21.2: 137-163.
DeRose, Stephen J. 1988. Grammatical category disambiguation by statistical optimization. Computational Linguistics 14.1: 31-39.
Elworthy, D. 1994. Does Baum-Welch re-estimation help taggers. Proceedings of the Fourth Conference on Applied Natural Language Processing, ACL.
Greene, B. B. & Rubin, G. M. 1971. Automatic grammatical tagging of English. Technical Report, Brown University. Providence, RI.
Hindle, D. 1989. Acquiring disambiguation rules from text. Proceedings of the 27th Annual Meeting of the Association for Computational Linguistics.
Klein, S. & Simmons, R. A computational approach to the grammatical coding of English words. Journal of the Association for Computational Machinery 10: 334-347.
Kupiec, J. 1992. Robust Part-of-speech tagging using a hidden Markov model. Computer Speech and Language 6.
Larsen, Richard J. & Marx, Morris L. 1986. An Introduction to Mathematical Statistics and its Applications. Englewood Cliffs, NJ: Prentice-Hall.
Maltese, G. & Mancini, F. 1991. A technique to automatically assign parts-of-speech to words taking into account word-ending information through a probabilistic model. Proceedings, Eurospeech-91, 753-756.
Marshall, Ian. 1983. Choice of grammatical word-class without global syntactic analysis: Tagging words in the LOB corpus. Computers and the Humanities 17: 139-150.
Merialdo, Bernard. 1994. Tagging English text with a probabilistic model. Computational Linguistics 20.2: 155-172.
Rabiner, Lawrence R. 1989. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE 7.2: 257-286.
Schütze, Hinrich. 1993. Part-of-speech induction from scratch. Proceedings of the 31st Annual Meeting of the Association for Computational Linguistics, 251-258.
Tapanainen, Pasi & Voutilainen, Atro. 1994. Tagging accurately: don't guess if you don't know. Technical Report, Xerox Corporation.
Viterbi, A. J. 1967. Error bounds for convolutional codes and asymptotically optimal decoding algorithm. IEEE Transactions on Information Theory 13: 260-269.
Weischedel, R., Meteer, M., Schwartz, R., Ramshaw, L. & Palmucci, J. 1993. Coping with ambiguity and unknown words through probabilistic methods. Computational Linguistics 19.