
MindNet
:从文本中获取并组织语义信息by Stephen D.Richardson, William B.Dolan, Lucy Vanderwende
(Doubtfire草译)
三位作者中,Richardson在1997年完成博士学位论文:Determining similarity and inferring relations in a lexical knowledge base, City University of New York.Vanderwende在1996年完成博士论文:The analysis of noun sequences using semantic information extracted from on-line dictionaries, Georgetown University, Washington,DC.
摘要:作为从两种机器可读的词典(MRD)中自动构建起来的词汇知识库,MindNet包含了几个跟以往的MRD不同的特征。然而,超出作为静态资源本身的意义,MindNet代表了从自然语言文本中获取、组织、访问、开采语义信息的一般方法。本文对MindNet的特点,以及如何创建它和如何把这种方法拓展到词典文本之外的语料范围,所应采取的步骤,做了概括介绍。
1 引言在这篇文章中,我们对
MindNet目前已有的显著特征和功能进行了描述,并跟相关工作进行了比较。我们还讨论了把MindNet的方法拓展到处理其他语料(尤其是微软百科全书Microsoft Encarta 98 Encyclopedia)以及有关MindNet的未来的计划。对于跟MindNet的创建和使用有关的细节和背景知识,读者可以参阅Richardson(1997), Vanderwende(1996), 和Dolan et al.(1993)。 2 MindNet是全自动化构建的MindNet
是全自动化处理过程产生的,基于一个广域的自然语言分析器(broad-coverage parser)。MindNet的一个最新版本就是作为标准的回归处理(regression process)的一部分,规则地构建起来的。基础系统或分析语法的日常变动(daily changes)带来的问题都很快地得到确认和修订。尽管已经有很多的使用自动方法从词典释义中抽取信息的研究(比如
Vossen 1995, Wilks et al.1996),手工编制的知识库,譬如WordNet(Miller et al.1990)仍然是受关注的研究。Euro WordNet(欧洲WordNet工程,Vossen 1996)尽管保持了WordNet的传统,但还是在获取词典内容方面采用了半自动的处理路线。在自然语言处理领域之外,我们认为,自动方法,比如
MindNet所用的方法,为在能支持常识推理的规模上抽取世界知识提供了最可信的前景。同时,我们承认,人工来对这些信息进行判断,以在产品水平上确保精确性和一致性,是潜在地需要的。 3 广域分析(Broad-coverage parsing)MindNet
中包含的语义信息的抽取,采用了跟微软Word 97中用来做句法检查非常类似的广域句法分析器。这个句法分析器产生句法分析树以及更深的逻辑表达式(deeper logical forms),应用规则产生相应的语义关系结构。该分析器不是专门为处理词典释义定做的。对这个分析器所做的所有增强改进,都是被调整用来控制一般文本的巨大差异性的,词典释义相对简单规范,是这样的一般性文本的一个非常合适的子集。在使用启发式模式匹配方法处理词典释义方面已有相当多的尝试,尤其是构造好的释义分析器(比如Wilks et al.1996, Vossen 1995),以及通用覆盖面的句法分析器(general coverage syntactic parser, 比如Briscoe and Carroll 1993)。但是,这其中还没有在整个词典中产生广泛的语义关系方面做成功的,而MindNet在这方面已经有了成品。
Vanderwende(1996)
描述了在用来抽取MindNet中包含的语义关系所采用的方法的细节。一个真正的广域句法分析器是实现这个过程的基础。它也是拓展到其他信息源文件,比如百科全书和文本语料库,进行处理的基础。 4 带标记的语义关系(Labeled, Semantic relations)下面是
MindNet中所用到的不同类型的语义关系的标记(24种关系):Attribute属性 |
Goal目标 |
Possessor领有者 |
Cause原因 |
Hypernym上位 |
Purpose意图 |
Co-Agent联合施事 |
Location场所 |
Size大小 |
Color颜色 |
Manner方式 |
Source源 |
Deep_Object深层宾语 |
Material材料 |
Subclass子类 |
Deep_Subject深层主语 |
Means方法 |
Synonym同义 |
Domain领域 |
Modifier修饰语 |
Time时间 |
Equivalent同位 |
Part部分 |
User使用者 |
Table 1: current set of semantic relation types in MindNet
(目前在MindNet中用到的语义关系)这些关系类型可能跟用于从词典创建网络结构的简单的共现统计形成了对照(做过这方面研究的包括
Veronis and Ide 1990, Kozima and Furugori 1993, 和Wilks et al. 1996)。带标记的关系,尽管获取很困难,但对解决结构附加和词汇方面的歧义问题非常有用。一方面很多研究人员已经承认语义关系标记的用处,但另一方面他们有时候,或是因为不能(比如缺乏足够强大的分析器),或是因为不愿(比如只注重纯统计的方法),来努力获取这样的语义知识。这种不足限制了词对子(
word pairs 如 river/bank, Wilks et al.1996 和write/pen, Veronis and Ide 1990)的刻画描述过于简单化,而MindNet的带标记语义关系正好规定了这方面的更详细的关系信息,比如bank是river的一部分(Part),pen是write的方式/手段(Means)。 5 语义关系结构(Semantic relation structures)从释义和例句中自动抽取语义关系,为
MindNet产生一个这些关系的层级结构,表示全部的释义或例句。这样的结构在MindNet中被整个存贮起来,为本文下面几个部分将要介绍的处理过程中的一些环节提供关键的上下文。下面看一个关于car(汽车)的释义的语义关系结构的例子:car:
“ a vehicle with 3 or usually 4 wheels and driven by a motor, esp. one for carrying people ”
Figure 1: car的释义的语义关系结构
早期的基于词典的工作注重抽取聚合关系(paradigmatic relations),尤其是上位关系(比如car汽车是一种vehicle交通工具)。几乎没有例外,这些关系,以及其他组合关系(syntagmatic relations),就构成了有关的三元形式(Almost exclusively, these relations, as well as other syntagmatic ones, have continued to take the form of relational triples)(参见Wilks et al. 1996)。而这些关系所由产生的更大的上下文通常都不被保留。对带标记的关系而言,仅有少数的研究人员(最近Barriere and Popowich 1996)开始对从词典释义中抽取整体的语义结构感兴趣起来,尽管他们还没有报道已经抽取了多少重要的关系。
6 结构的完全倒置 (Full inversion of structures)在语义关系结构创建之后,它们在整个
MindNet数据库中被全部倒置(inverted)并被繁殖(propagated),被链接到每一个在其中出现的词上。下面就是一个从motorist(乘车者)的释义产生的,并且链接到car词条的这样一个倒置的结构的例子:motorist:
“ a person who drives, and usu. owns, a car ”(inverted)
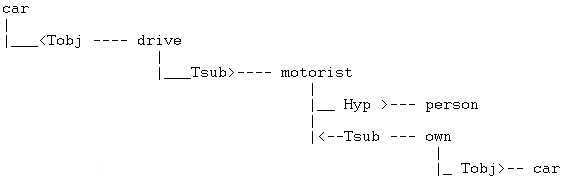
Figure 2: 从motorist的释义得来的倒置的语义关系结构。
那些从
MRD中产生出传播激活网络(spreading activation networks)的研究人员,包括Veronis和Ide(1990)以及Kozima和Furugori(1993),典型情况下,在他们生成的网络中都仅仅完成朝前链接(forward links),就是从headwords中心词/标题词到给它释义的词。一个词A没有跟任何中心词/标题词(该标题词的释义提到了这个词A)向后相关(be related backward to),也没有跟另外的在同一个释义中共现但不直接相关的词发生关系。但是,在MindNet存放的完全倒置的结构中,所有的词语都是交互链接的(cross-linked),不管它们出现在哪里。MindNet
中包含的倒置语义关系结构的大规模的网络使反对基于词典的方法的批评者也无话可说。Yarowsky (1992),以及Ide和Veronis (1993)曾指责从MRD中产生的LKB提供了一个满是斑点的语言知识库。现在,在其他方面的试验(Richardson 1997)显示了MindNet中所包含信息的覆盖广泛性。一些统计数据显示了目前
MindNet的规模(上千)以及产生它需要的处理时间。释义和例句来自朗文当代英语词典(LDOCE)以及美国传统词典(American Heritage Dictionary)第三版。Dictionaries used |
LDOCE & AHD3 |
Time to create(on a P2/266) |
7 hours |
Headwords |
159,000 |
Definitions(N,V,ADJ) |
191,000 |
Example sentences(N,V,ADJ) |
58,000 |
Unique semantic relations |
713,000 |
Inverted structures |
1,047,000 |
Linked headwords |
91,000 |
Table 2: MindNet
当前版本的一些统计资料 7 加权的路径 (Weighted paths)倒置的语义关系结构使得访问每个结构的根词(
root word)间的直接和间接关系非常方便。而所谓的结构就是MindNet的词条的中心词,中心词之外的其他词包含在结构之中。这些关系连接在一起,在两个词之间构成语义关系路径(semantic relation paths)。比如,car和person之间的语义关系路径是:car <--- Tobj ---- drive ---- Tsub -----> motorist --- Hyp -----> person
一个扩展的语义关系路径是在两个不同的倒置语义结构中从子路径产生出来的。比如,
car和truck不直接语义相关。但是,如果跟随下面的语义关系连接, car --- Hyp ---> vehicle和Vehicle <---- Hyp --- truck,就能得到 car --- Hyp ---> vehicle <--- Hyp --- truck。充分约束的、扩展的语义关系路径已经证明,词跟词之间的关系不被连接起来,就没有用。语义关系路径自动加权反映显著的程度。
MindNet中的权重是基于平均最大概率(averaged vertex probability)进行计算的,可以中等频率给出优先的语义关系,详细情况可参见Richardson (1997)。同样目标的加权方案在Braden-Harder(1993)和Bookman(1994)的工作中也有介绍。 8 相似性和推理( Similarity and inference )许多研究者,在基于词典和基于语料库的阵营中都有,已经在研究辨识词之间的相似性的方法上进行了广泛的工作,因为相似性确定在很多词义排歧问题上和参数平滑/推理等处理过程中是关键。但是,一些研究者在辨识替代相似性(substitutional similarity)和一般相关性(general relatedness)上失败了。MindNet的相似性处理主要是注重对替代相似性进行估计,但也提供产生一般相关词的聚类的功能。
两个通用的策略已经在辨识替代相似性的文献中有所描述。其中之一是基于辨识词之间的直接的、聚合的关系,比如上位(Hypernym)和同义(Synonym)。例如,在WordNet中聚合关系已经被多次用来确定相似性,包括Li et al. (1995)和Agirre and Rigau(1996)。另一个策略是基于辨识组合关系,相似的词应该在跟其他词组合方面表现出相似的性质。组合策略确定相似性经常基于对大语料库的统计分析,可以产生在类似的二元和三元上下文中出现的词的聚类。(比如Brown et al.1992, Yarowsky 1992),此外也包括相似的谓词―论元结构环境(predicate-argument structure contexts,比如Grishman 和 Sterling 1994)。
已有相当多的尝试,试图把聚合和组合相似性策略融合在一起(比如 Hearst 和 Grefenstette 1992,Resnik 1995)。但是,没有人已经完全把聚合和组合信息整合到一个单一的知识库(a single repository)中,就象MindNet所做的那样。
MindNet
相似性处理是建立在两个词语之间高分(top-ranked)的语义关系路径基础上的。比如,下面是MindNet中,pen和pencil之间一些高分的语义关系路径pen <--- Means --- draw --- Means ---> pencil |
pen <--- Means --- write --- Means ---> pencil |
pen --- Hyp ---> instument <--- Hyp --- pencil |
pen --- Hyp ---> write --- Means ---> pencil |
pen <--- Means --- write <--- Hyp --- Pencil |
Table 3: pen和pencil之间的高权值语义关系路径
在上例中,语义关系的对称模式清楚地在很多路径上显示出来。这引导我们做出这样的假设,在MindNet中,相似的词典型情况下是由相当多的对称的路径连接的,而其他的词则不是这样。
在几个完成了的试验中,来自义类词典thesaurus和反义类词典anti-thesaurus(后者包括了不相似的词)的词对(word pairs),在训练阶段被用来确认语义关系路径,指示相似性。然后这些路径模式在测试阶段被用来确定未知词对(unseen word pairs)的替代相似性或不相似性(dissimilarity)(Richardson 1997描述了算法)。下面的结果显示了我们的综合方法的能力。这是唯一采用了聚合和组合关系两种策略的方法。
Training: over 100,000 word pairs from a thesaurus and anti-thesaurus produced 285,000 semrel paths containing approx. 13,500 unique path patterns. |
|||||||||
Testing: over 100,000 (different) word pairs from a thesaurus and anti-thesaurus were evaluated using the path patterns. Similar correct 84% Dissimilar correct 82% |
|||||||||
Human benchmark: random sample of 200 similar and dissimilar word pairs were evaluated by 5 humans and by MindNet:
|
Table 4:
相似性试验的结果这个功能强大的相似性处理也可以用来拓展
MindNet的关系覆盖面。跟在基于语料库的方法中利用相似性确定来推断缺席的n元或三元(triples)相当(比如Dagan et al.1994和Grishman and Sterling,1994),一个推理程序已经开发出来,允许在MindNet中从已有的语义关系推理出当前没有的语义关系。例如,如果关系watch --- Means ---> telescope在MindNet中没有,它应该可以被推理出来。首先是找到watch和telescope之间的语义关系路径,测试这些路径,考察是否有其他词跟telescope之间构成Means关系,然后检查该词跟watch之间的相似性。结果是observe满足这个路径上的条件:watch --- Hyp ---> observe --- Means ---> telescope
因此,它可能被推理出来,一个人可以
telescope的Means watch。推理和相似性处理的无缝集成(seamless integration),二者都利用了加权、由倒置的语义关系结构推导出的扩展路径,是这种方法的独特之处。 9 MindNet的排歧 (Disambiguating MindNet)在MindNet 创建过程中,一个额外的处理层次寻求提供意义辨识。典型地,词义排歧(WSD)在分析释义和例句时会碰到,紧随在逻辑形式的构建之后(Braden-Harder,1993)。分析中的细节信息,包括形态和句法,急剧地减少了可以被似是而非地安到每个词头上的意义的范围。词典结构的其他方面也被开发利用了(exploited),包括跟特别意义相关联的领域信息(例如棒球)。
在处理用于创建MindNet的上下文语料之外的标准输入文本时,WSD主要依赖MindNet提供的有多少词义互相链接的信息。为帮助减轻在MindNet创建开初时碰到的这个自引导问题,我们已经试验了一个两道关口WSD方法(two-pass approach toWSD)。
在第一个关口(pass),MindNet的一个版本,不包括WSD的版本,被构建起来。结果是一个语义网络,但是包含相当多的关于意义指派的“周围环境”信息(“ambient”information)。例如,处理spin 101的释义:(of a spider or silkworm) to produce thread ... 产生一个语义关系结构,在这个语义结构中,意义结点spin101靠一条Deep_Subject路径跟没有排歧的形式spider链接。在后续的第二个关口,这个信息被WSD利用,在不相关的释义中指派意义101给词spin :wolf_spider 100: any of various spiders ... that ... do not spin webs。这种自举引导反映了我们所用方法的广泛性。正如我们将在下一个小节将要讨论的:全面而精确地排除了歧义的MindNet允许我们在碰到词典领域之外的自由文本时将意义加到词上。
10 作为一种方法论的MindNet (MindNet as a methodolgy)MindNet
的创建从未打算就以创建本身为目的或者结束。相反,我们强调建立一个覆盖范围广泛的自然语言处理理解系统。我们考虑创建MindNet的这种方法来组织一系列通用工具,用来从自然语言文本中获取、组织、访问、开发语义信息。我们用来构建
MindNet的技术大部分是基于规则的。但是我们达到这些表达式,MindNet的全部结构可以被认为式主要依赖统计的。如果不仅仅是一瞥表面的情况,会发现我们跟传统的基于语料库的方法有更多的共同之处。但是,我们超越这些方法的一个优点是,利用系统的句法分析、逻辑表达式、词义排歧等组成成分得到的丰富结构。我们在MindNet的上下文中用到的统计学允许更丰富的诗韵,因为数据本身是更丰富的。( The statistics we use in the context of MindNet allow richer metrics because the data themselves are richer. )我们以此种方法进入(
foray)自由文本处理领域的头个尝试已经完成。 LDOCE和AHD3中的58000例句在我们目前版本的MindNet的创建中已经被处理过(见前面表2)。为把我们的假设放到更严格的测试中,我们最近已经开始着手微软百科全书整个文本的消化工作(assimilation)。尽管仅仅考虑到规模这已经表现出几个新的挑战,但我们已经成功地完成了第一个关口(first pass),并已经产生和增加了微软百科全书中的语义关系结构到MindNet中。在这个步骤中的统计资料如下:Processing_time(on a P2/266) |
34 hours |
Sentences |
497,000 |
Words |
10,900,000 |
Average_words/sentence |
22 |
New_headwords_in_MindNet |
220,000 |
New_inverted_structures_in_MindNet |
5,600,000 |
Table 5:
微软百科全书(Microsoft Encarta98)的统计数据除进军词典之外的英语语料,我们还打算把同样的方法应用到其他语言上。目前我们正为
3种欧洲语言和3种亚洲语言开发NLP系统,包括法语、德语、西班牙语;汉语、日语、朝鲜语。这些语言的句法分析器已经相当先进并已经公开展示过。一旦这些语言的系统成熟,我们将创建这些语言各自相应的MindNet,就象我们在英语方面的做的工作那样,首先是处理机器可读的参考材料(比如MRD词典),然后就是增加从语料中收集到的信息。 11 参考文献 (暂时略)