2. The state of the art in corpus linguistics
GEOFFREY LEECH
2.1 Historical background
When did modern corpus linguistics begin? Should we trace it back
to
the era of post-Bloomfieldian structural linguistics in the USA?
This was
when linguists (such as Harris and Hill in the 1950s) were
under the
influence of a positivist and behaviourist view of the
science, and
regarded the 'corpus' as the primary explicandum of
linguistics.(1) For such
linguists, the corpus -- a sufficiently large body
of naturally occurring
data of the language to be investigated -- was
both necessary and
sufficient for the task in hand, and intuitive
evidence was a poor second,
sometimes rejected altogether. But
there is virtually a discontinuity
between the corpus linguists of that
era and the later variety of corpus
linguists with whose work this
book is concerned.
The discontinuity can be located fairly precisely in the later 1950s.
Chomsky had, effectively, put to flight the corpus linguistics of the
earlier generation. His view on the inadequacy of corpora, and the
adequacy of intuition, became the orthodoxy of a succeeding gener-
ation of theoretical linguists:
Any natural corpus will be skewed. Some sentences won't occur
because
they are obvious, others because they are
false, still others because they are
impolite. The
corpus, if natural, will be so wildly skewed that the description
would be no more than a mere list.
(Chomsky, University of Texas, 1962, p. 159)
In the following year or two, the founders (as is now clear in
hindsight) of a new school of corpus linguistics began their work,
little noticed by the mainstream. In 1959 Randolph Quirk announced
<page 9>
his plan for a corpus of both spoken and written British English --
the
Survey of English Usage (SEU) Corpus, as it came to be known.
Very shortly
afterwards, Nelson Francis and Henry Kucera
as-
sembled a group of 'corpus-wise'
linguists at Brown University, and
out
of their deliberations eventually came the Brown Corpus -- a
'standard sample' of printed American English 'for use
with digital
computers' (Francis and
Kucera 1979/1982). We can regard the
second era of corpus
linguistics as that which began with the
collection of the SEU and Brown
corpora in 1961 and has been
dominated by the power of the computer; and
yet the SEU Corpus
was not conceived of as a computer corpus.(2) The drawback of
computer corpora -- their tendency to disfavour spoken data (because
of problems of transcription and input) -- did not therefore apply to
the SEU, which was to be (approximately) 50 per cent spoken and
50 per
cent written. Its particular strength was to be in the 'non-
computable'
data of speech.
It was left to the vision and perseverance of Jan Svartvik, with the
team he assembled at Lund, to capitalize on the combined strengths
of
the Brown and SEU corpora.(3) His Survey of
Spoken English
began, in 1975, the arduous task of rendering
machine-readable the
unscripted spoken texts of the SEU corpus. The
arduousness was
especially due to the detailed prosodic coding in which
the texts had
been transcribed. The resulting London-Lund Corpus (LLC)
remains
to this day an unmatched resource for the study of spoken
English.(4)
In the thirty years since 1961, corpus linguistics (of the newer
computational variety) has gradually extended its scope and in-
fluence, so that, as far as natural language processing by computer is
concerned, it has almost become a mainstream in itself.(5) It has not
revived the American structural linguist's claim of the all-sufficient
corpus, but the value of the corpus as a source of systematically
retrievable data, and as a testbed for linguistic hypotheses, has
become widely recognized and exploited.(6) More important,
perhaps,
has been the discovery that the computer corpus offers a new
methodology for building robust natural language processing systems
(see 3 below).
2.2 The corpus data explosion: bigger means better?
At a basic level, the resurgence of corpus linguistics can be measured
in terms of the increasing power of computers and of the exponen-
<page 10>
tially increasing size of corpora, viewed simplistically as large bodies
of computer-readable text. The Brown Corpus (like its British
counterpart, the LOB Corpus -- see Johansson et al. 1978) can be
thought of as a 'first-generation' corpus; its million-word bulk seemed
vast by the standards of the earlier generation of corpus linguistics.(7)
But this
size was massively surpassed by a 'second generation' of the
1980s
represented by John Sinclair's Birmingham Collection of
English Text
(Renouf 1984, Sinclair 1987) and the Longman/
Lancaster English Language
Corpus, which benefited from the
newer technology of the KDEM optical
character-recognition device,
freeing corpus compilation from the logjam
of manual input. And
perhaps the title 'third generation' may be given to
those corpora,
measured in hundreds of millions of words, almost all in
commercial
hands, exploiting the technologies of computer text processing
(in
publishing and in word-processing, for example) whereby huge
amounts of machine-readable text become available as a by-product
of
modern electronic communication systems. Machine-readable
text collections
have grown from one million to almost a thousand
million words in thirty
years, so it would not be impossible to
imagine a commensurate
thousand-fold increase to one million
million word corpora before 2021.
2.2.1 Why size is not all-important
To focus merely on size, however, is naive -- for four reasons.
Firstly, a collection of machine-readable text does not make a
corpus.
The Brown and SEU corpora were carefully designed as
systematic
collections of samples, so as to have face-validity as
representative of
'standard' varieties of English. The third-generation
corpora have been
more in the nature of computerized archives (of
which the best-known
example is the Oxford Text Archive: cf.
Oxford University Computing
Service 1983): that is, they have been
collected more or less
opportunistically, according to what sources
of data can be made available
and what chances for collection arise.
The Birmingham Collection is an
interesting intermediate case: data
have been collected beyond the bounds
of what is required for the
lexicographic purpose in hand, so that an
ongoing archive -- what
Sinclair and his associates call a 'monitor
corpus' (Renouf 1987:21)
-- exists alongside the lexicographic 'main
corpus'. New initiatives,
notably the ACL/DCI (Association of
Computational Linguistics
<page 11>
Data Coding Initiative) in the USA, aspire to make the concept of
an
archive almost comparable in scope to that of a national copy-
right
library.(8) But
there still remains the task of 'quarrying' from
such a vast data resource
the corpus needed for a particular purpose
-- for ultimately, the
difference between an archive and a corpus
must be that the latter is
designed or required for a particular
'representative' function.(9) In terms of
'representativeness' we may
distinguish relatively general-purpose
corpora, such as the Brown
and SEU corpora, from corpora designed for a
more specialized
function -- a domain-specific corpus representing the
language of the
oil industry, for example.(10)
Secondly, the vast growth in resources of machine-readable text
has
taken place exclusively in the medium of written language. Until
speech-recognition devices have developed the automatic input of
spoken language to the level of present OCR (optical character-
recognition) devices for written language, the collection of spoken
discourse on the same scale as written text will remain a dream of
the
future. The transcription of spoken discourse into written form,
as a
necessary step in the collection of spoken corpora, is a time-
consuming
process fraught with problems.(11) In this
context, the
abiding importance of the London-Lund Corpus must again be
emphasized.
Thirdly, while technology advances quickly, human institutions
evolve
slowly. This platitude has particular relevance to the collection
and
distribution of computer corpora, where that most slowly
evolving of human
institutions -- the legal system -- retards the full
availability of the
resources which technology makes possible. The
law relating to copyright
-- not to mention other legally enforceable
rights such as that relating
to confidentiality -- forbids the copying of
text (including the inputting
of texts to a computer) without the
express permission of the copyright
holder, typically the originator,
author or publisher of the text. Since
the granting of copyright
permission can be held to have a commercial
value, it is not likely to
be granted on a carte blanche basis, and
substantial fees are liable to
be charged. Although certain corpora (such
as the Brown, LOB and
LLC) are distributable for non-commercial research
applications,
others are not publicly available at all, and the concept of
a corpus
which is in the public domain -- available unconditionally for
all
users -- does not so far exist, except for texts too old to be in
copyright.
<page 12>
Fourthly, another platitude -- current within the computer world --
is
that, while hardware technology advances by leaps and bounds,
software
technology lags like a crawling snail behind it. In the
present context,
software may be taken to include not the 'raw' or
'pure' corpus, which can
be collected more or less automatically in
its original machine-readable
form, but the annotations which
linguists and others may add to it, and
the computer programs
designed to process corpora linguistically. Clearly,
a corpus, how-
ever large, when stored orthographically in
machine-readable form,
is of no use unless the information it contains can
become available
to the user. Therefore, as a first step it is necessary
for the corpus-
derived information to be accessed through a search and
retrieval
facility, a simple example of which is a KWIC concordance
program.
Such programs are the most familiar and basic pieces of software
to
use with a corpus; more sophisticated search and retrieval packages
such as the Oxford Concordance Program (OCP), WordCruncher
and KAYE
are known to many users.(12) But to make
more linguisti-
cally interesting use of a corpus, it is necessary to
analyse the corpus
itself, and therefore to develop tools for linguistic
analysis. Such
tools are at present relatively primitive, with a
consequent limit on
the extent to which large corpora can be
linguistically exploited.
2.2.2 The need for annotated corpora
Concordance programs essentially sort and count the objects they
find
in a corpus -- which, in the 'raw' corpus, are words, punctuation,
and the
characters of which words are composed. Unless appropriate
additional
information is somehow built into the corpus, the con-
cordancer cannot
tell the difference between I (personal pronoun)
and I
(roman numeral); between minute (noun) and minute (adjec-
tive); or between lying (telling untruths) and lying (in a
recumbent
posture). How is this information to be provided? Can the
analysis,
as in the post-Bloomfieldian paradigm, be induced from the
corpus
by discovery procedures, or does the researcher need to impose
distinction on the text by means of human 'intuition' or analysis?
2.2.3 Arguments in favour of large corpora
Shortly, I will answer the above question by pointing to the variable
division of labour between human analyst, corpus and software; but
<page 13>
before leaving the issue of size, I wish to balance my above
deprecation of large corpus size by arguments in its favour.
The corpus linguist of the 1950s could entertain without too much
difficulty the idea of a corpus providing the data for an exhaustive
description of a language. (13) This was
probably because the linguists
of that day focused on phonemics and
morphophonemics -- levels
where the inventory of linguistic items is small
by comparison (for
example) with syntax or the lexicon. When Chomsky
shifted the
centre of attention from phonology to syntax, he was able
effectively
to debunk the notion that the corpus could provide a
sufficiency of
data. He argued that the syntax of a language is a
generative
system, producing an infinite number of sentences from a finite
number of rules. This illustrates how the notion of what is an
adequate corpus shifts significantly as one moves from one linguistic
level to another. However, Chomsky in his turn could not have
conceived, in the 1950s, of a corpus of 500 million words capable of
being searched in a matter of minutes or hours. While it is unlikely
that foreknowledge of such a phenomenon would have changed
Chomsky's
view of corpora at that time (see Section 2.1 above), we
can see, in
historical retrospect, how the availability of vastly
increasing computer
corpus resources has enabled syntactic and
lexical phenomena of a language
to be open to empirical investigation
on a scale previously unimagined.
Ironically, this development has caused investigators to become
aware,
with a degree of realism not previously possible, of the open-
ended
magnitude of languages not only in their lexis (where the
openness of the
linguistic system has long been acknowledged) but
also in their syntax,
where recent research has indicated that syntac-
tic rule systems are
themselves open-ended, rather than a closed set
such as Chomsky envisaged.
(14) However,
this sobering awareness
should not dishearten the corpus linguist. Whereas
the view of a
corpus as an exhaustive reservoir of data is scarcely
tenable today,
our new 'megacorpora' can provide the means for
training and
testing models of language so as to assess
their quality. The statistical
measure known as perplexity (see
Jelinek 1985b) provides an evalu-
ation of how good a grammar (or language
model) is in accounting
for the data observed in a corpus. Here is a
precise measurement
comparable to the 'simplicity measures' which Chomsky,
in his
earlier writings, regarded as a basis for the evaluation of
linguistic
descriptions (see Chomsky 1965: 37-47). Corpus linguistics need
no
<page 14>
longer feel timid about its theoretical credentials, nor does the
earlier Chomskyan rejection of corpus data carry such force. (15) At
the
same time, the development and testing of probabilistic models
of language
require the availability of very large corpora.
2.3 The processing of corpora: how humans and machines
interact
The linguistic annotation or analysis of corpora demonstrates a need
for a partnership between man and machine, or (drawing the lines
in a
slightly different way) between human processing, computer
processing and
corpus data. Neither the corpus linguist of the 1950s,
who rejected
intuition, nor the generative linguist of the 1960s, who
rejected corpus
data, was able to achieve the interaction of data
coverage and insight
that characterizes the many successful corpus
analyses of recent years.
(16)
There are a number of ways in which human, software and corpus
resources can interact, according to how far the human analyst
delegates to the computer the responsibility for analysis. At one end
of the scale, the computer program (e.g. a concordance program) is
used simply as a tool for sorting and counting data, while all the
serious data analysis is performed by the human investigator. (Most
of
the studies mentioned in Note 16 belong to this category.) At the
other
extreme, the human analyst provides no linguistic insight, just
programming ability; the machine discovers its own categories of
analysis, in effect implementing a 'discovery procedure' . Such ex-
periments as have been carried out in this field have been mostly
limited to simple tasks, such as the discovery of English word classes
by clustering words on the basis of their distribution. (17) Their results
are fascinating in showing, on the one hand, some striking resem-
blances between the classes discovered by the machine and those
recognized by grammatical tradition (prepositions and modals, for
example, emerge as clearly distinguishable classes), and on the
other,
that the classes found often correspond only partially to
established
English word classes (her, for example, falls uneasily
between
possessives and objective pronouns, since the program
cannot account for
word class ambiguity). Such experiments appear
to show that the machine
can discover some, but not all, of the
truth; they provide reassurance to
those, like myself, who believe
<page 15>
that successful analysis depends on a division of labour between the
corpus and the human mind.
Somewhere between the two poles of unequal collaboration men-
tioned
above there is a third type of human-machine partnership,
where the human
linguist's role can be characterized as that of an
'expert' whose
specialized knowledge is programmed into a com-
puter system. Consider the
example of a grammatical word-tagging
system. (18) The human
expert here -- say, a grammarian or a lexico-
grapher -- proposes a set-of
grammatical tags to represent the set of
English word categories; a
lexicon and other databases are built,
making use of these categories; and
programs are written to assign
an appropriate word tag to each of the word
tokens in the corpus.
The program achieves its task at a success rate of x
per cent (x being
typically in the region of 96-7 per cent); the errors
that it makes --
judged to be errors on independent linguistic grounds --
are fed back
to the expert, who then proposes modifications to the
original set of
categories, or the program, or both. The program and
analytic
system can now be tested on fresh corpus material, and it can be
observed how far the modifications have brought about a better
success
rate (see Figure 2.1).
In this model, then, there is a truly interactive relation between
analyst, software and corpus, whereby two different analyses can be
<Figure
2.1> 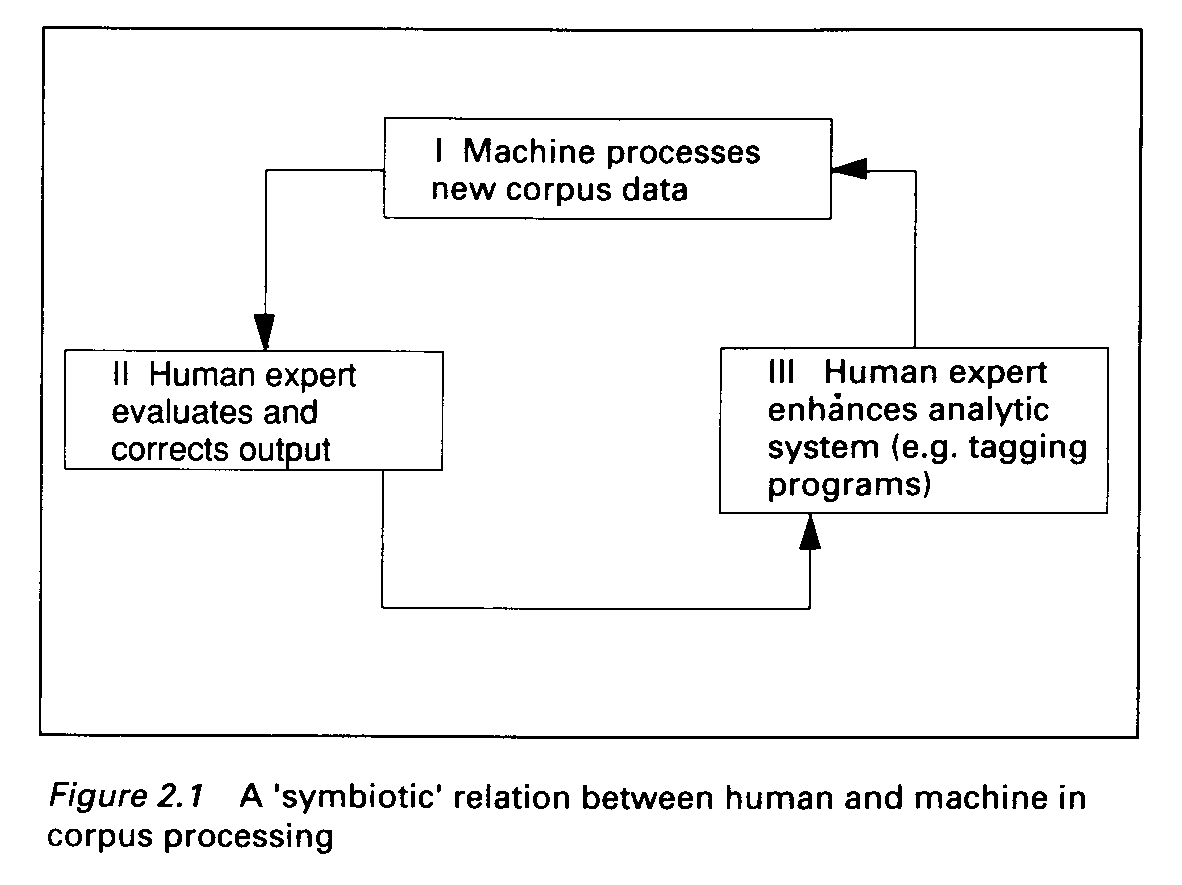
<page 16>
compared and evaluated by an independent criterion of success.
After
the human post-editor has completed the task of annotating
the corpus, the
results are twofold: (a) an analytic device (in this
case an improved
grammatical tagger), and (b) an analysed, or
annotated, corpus. The
symbiosis is evident in the relation between
the analytic device, which
brings about an analysis of the corpus,
and the analysed corpus, which
(through feedback) brings about an
improvement in the analytic device (cf.
Aarts, this volume).
This symbiosis is all the more necessary when we add a prob-
abilistic
dimension. Probabilities, like corpora,(19) were given no
place in the Chomskyan paradigm, but in areas such as speech
recognition, probabilistic models have been found to be more
capable
than non-probabilistic models,(20) even though
the latter may
claim greater verisimilitude as imitations of human
language pro-
cessing. While it is evident that detailed probabilities are
not
'intuitively' available to the native speaker or the linguist,
realistic
estimates of probability can be made on the basis of observed
corpus frequencies. The most successful grammatical tagging systems
appear to be those based on a simple finite-state grammar with
probabilities (derived from corpus frequency data) assigned to the
transitions between states -- i.e. a Markov process model.(21) An
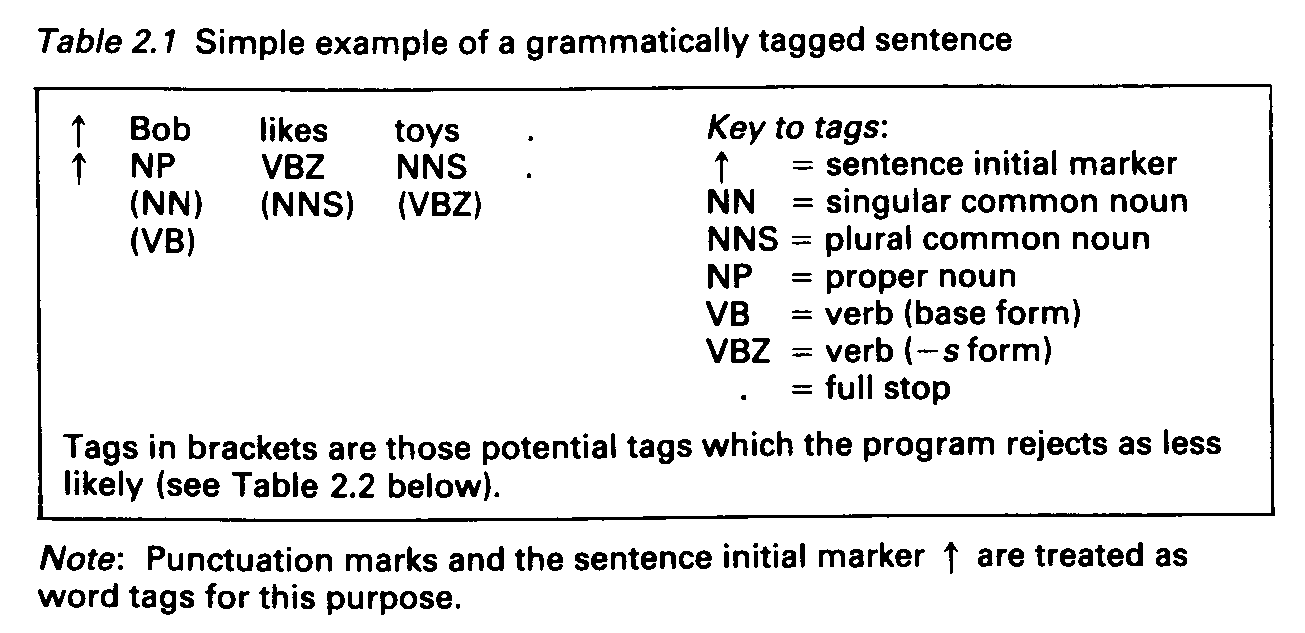
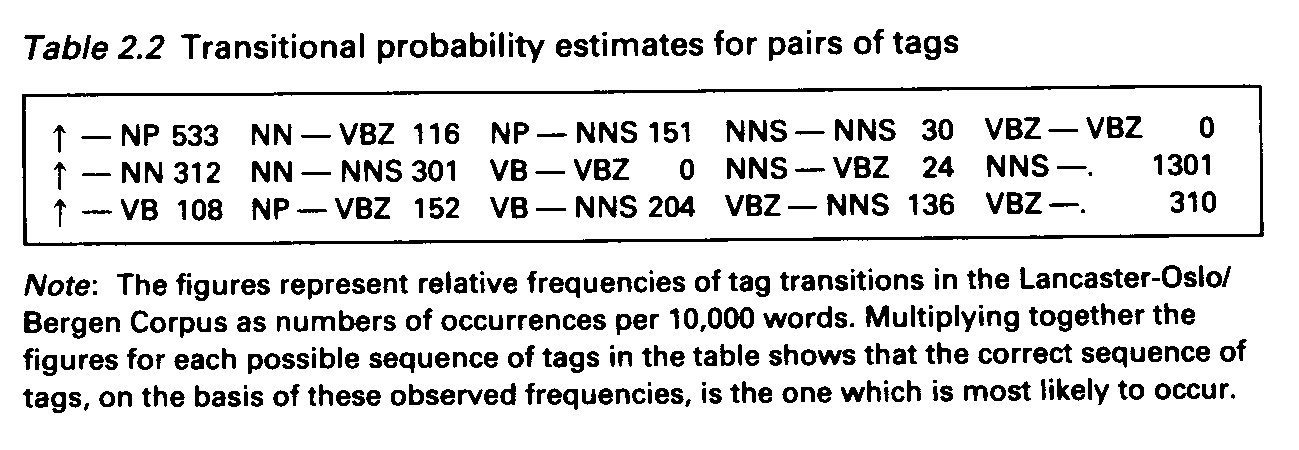
essential source of data for such a system is a grammatically tagged
corpus supplying the transitional frequencies between tags which
become the de facto estimates of transitional probabilities of the
Markov process grammar (see Tables 2.1 and 2.2).
The fact that such a simple model, which Chomsky rejected as
inadequate
in the opening chapters of Syntactic Structures (1957:
<page 17>
21), proves unexpectedly adequate to the task of automatic gram-
matical tagging and throws an interesting light on the contrast
between the non-probabilistic and cognitive orientation of
Chomskyan
linguistics, and the probabilistic non-cognitive orien-
tation of much
corpus-based research. The 'cognitivists' will say that
a machine for
manipulating probabilities cannot represent a realistic
model of language,
i.e. a model of human linguistic knowledge.
From their point of view, the
probabilities at best provide a means
whereby the machine, lacking human
knowledge and cognitive
abilities, can achieve a limited resemblance to
human ability, like
that of an ingenious mechanical doll full of springs
and machinery.
The 'probabilists' will say that the model is a model of
human
linguistic behaviour -- precisely that, and no more; but it may even
so provide insights into the psychology of language, on the grounds
that probabilities enter into human language processing and under-
standing to an extent that has been overlooked (see Sampson
1987b).
One thing in favour of probabilistic language processing
systems is that
they are eminently robust. They are fallible, but they
work; they
produce a more or less accurate result, even on un-
restricted input data,
in a way that outperforms most rule-driven
language modelling systems.
2.3.1 Self-organizing methodology
Here, brief mention should be made of a more advanced model of
the
partnership between human and machine in the development of
probabilistic
language models, one which gives a larger role to the
machine. The major
disadvantage of the symbiotic model described
above is that it requires
massive human intervention at two points:
(a) at an initial stage, where
an extensive manual corpus analysis is
<page 18>
needed in order to arrive at preliminary probabilistic estimates for
the language model; and (b) at the crucial stage of diagnosis of
errors in the corpus analysis, and the feedback of those errors into
the corpus analysis. I call the human role here 'massive' because the
analysis of a million words by hand (which may be what is needed to
give the minimum satisfactory result in terms of probabilistic
grammar) requires the dedication of many thousands of human
hours to
the work.
A self-organizing methodology (see Bahl, Jelinek and Mercer
1983) is
one which avoids the human feedback stage intervening
between one
iteration of model enhancement and another. The
basic idea is that the
machine 'learns' to improve its language model
on the basis of the data it
encounters and analyses. To start the
iterative process, it is sufficient
to have some rough initial estimates
of probability. The iterative process
constitutes the training of the
language model so as to adjust its
probabilities in order to maximize
the likelihood, according to the model,
of the occurrence of the
observed corpus data (see Jelinek 1985a, Sharman
1989a: 33-6). At
present, the training of language models by
self-organization is
extremely demanding on computer resources, and only
the largest
computers are adequate to the task. In the future, as
computers
increase in storage and processing power, we may hope that self-
organizing methodology will take over much of the human effort at
present invested in corpus analysis. This becomes all the more
necessary as we develop more complex probabilistic models and the
opportunity arises for these to be trained and tested on larger and
larger corpora.
In Section 2.3 I have presented four different paradigms of
research
balance between the role of the human analyst and the
computer. These can
now be listed in the form of a scale, from most
human intervention to
least human intervention:
(1) 'Data retrieval model'
Machine provides the data in a convenient
form.
Human analyses the data.
(2) 'Symbiotic model'
Machine presents the data in (partially) analysed
form.
Human iteratively improves the analytic system.
(3) 'Self-organizing model'
<page 19>
Machine analyses the data and iteratively improves its analytic
system.
Human provides the parameters of the analytic system and the
software.
(4) 'Discovery procedure model'
Machine analyses the data using its own
categories of analysis,
derived by clustering techniques based on data.
Human provides the software.
One example of corpus annotation that I have mentioned is grammatical
tagging -- the assignment of grammatical word-class labels to
every
word token in a corpus. A consequence of the corpus analysing
methodology
outlined in Section 2.3 above is an annotated corpus --
no longer the
'raw' (or 'pure') corpus which was originally input to
the computer but a
version in which linguistic information, of
particular kinds, is
exhaustively provided.
Once a computer corpus has been annotated with some kind of
linguistic
analysis, it becomes a springboard for further research; it
enables a
concordance program, for example, to search for grammatical
abstractions
(such as instances of the passive voice, of the
progressive aspect, of
noun-noun sequences, etc.) rather than for
words. Probably the most
important spin-off is the use of an
annotated corpus to provide initial
statistics for probabilistic language
processing (see Section 2.3 above).
At present, a number of different corpora have been grammatically
tagged and are available in tagged versions, for example the
Brown
Corpus, the LOB Corpus and the Spoken English Corpus
(SEC).(22) There are,
however, many other levels at which annotation
must eventually take place
if the corpus is to incorporate full
information about its linguistic
form. With speech corpora, phonetic
and phonemic labelling has a high
priority (see Moore 1989). The
prosodic annotation of the LLC is itself a
complex form of annotation
-- although in this case the annotation is also
a part of the transcription
of the text itself.
Beyond word tagging, higher levels of grammatical tagging can be
undertaken, as in the grammatically annotated part of the London-
Lund
Corpus (see Svartvik et al. 1982, Svartvik 1990). Various
<page 20>
syntactically analysed sub-corpora, known as treebanks, have come
into existence. They are 'sub-corpora' because, as already noted in
Section 2.3 above, the syntactic analysis, or parsing, of corpus sentences
is a laborious activity, and even the analysis of a million
words
(e.g. of the Brown or LOB Corpus) is a vast enterprise, so
that in
practice we have had to be content to build our treebanks
from subsections
of such corpora.(23) Recent
research at Lancaster,
however, has resulted in a simplified syntactic
analysis technique
known as 'skeleton parsing', which can be performed
very quickly
by human operators using a rapid input program (see Leech and
Garside 1991).
The annotation of corpora does not stop with parsing. Semantic
analysis
and discoursal analysis of corpora are likely to be the next
stage in this
development of corpus annotation. The annotation of
the LLC for discourse
markers (Stenstr鰉 1984b, 1990) is one
example of higher-level analysis.
Another example is an 'anaphoric
treebank' which is now being undertaken
(with IBM funding) at
Lancaster and which includes not only skeleton
parsing but also
markers of anaphor-antecedent relationships.
2.5 Where are we now, and where are we going?
I conclude this survey of the 'state of the art' in corpus-based
research by considering the present situation and future prospects
under three headings which identify priority areas both for immediate
and for longer-term development (see also Johansson, this
volume):
(1) basic corpus development
(2) corpus tools development
(3)
development of corpus annotations.
We are now in a position where corpus-based research has truly
taken
off, not only as an acknowledged paradigm for linguistic
investigation but
as a key contribution to the development of
natural language processing
software. Hence research on the three
fronts mentioned is likely to
attract not only academic attention but
also the governmental and
industrial funding that will be necessary
if the progress wished for is to
take place.
<page 21>
2.5.1 Basic corpus development
The basic acquisition, archiving, encoding and making available of
text
corpora has recently taken a big step forward in many countries.
A recent
unpublished survey of European language corpora, by A.
Zampolli,(24) showed corpus
development, either completed or in
progress, for sixteen European
languages. France (with its enormous
historical corpus of the Tr閟or de
la langue fran鏰ise) was a pioneer
in this field, but many other
countries have recently followed,
perhaps seeing the value of national
corpus resources from two
contrasting points of view: that of commercial
investment (e.g. for
dictionaries) and that of the patriotic investment in
a national
language. Zampolli's data for languages excluding English
showed,
in all, 365 million words already collected (the largest
quantities
being 190 million words of French and 60 million words of
Dutch),
and a further 63 million words planned. However, the gulf between
the quantities of written material (348 million) and of spoken
material (17 million) was all too obvious. English was excluded from
Zampolli's survey, but he noted that even in non-English-speaking
European countries, English corpora, and projects involving them,
were
pre-eminent over those of other languages.
In the English-speaking world, where up to now the largest
collections
of data have been those acquired (e.g. by IBM) for
industrial or
commercial research (see Section 2.2 above), a number
of public corpus
collection initiatives have recently begun or are
about to begin. The
Association for Computational Linguistics has
launched a Data Collection
Initiative (ACL/DCI) aiming initially at
a corpus of 100 million words,
largely of American English. The
corpus will be encoded in a systematic
way, using the Standard
Generalized Markup Language (SGML), in
coordination with a
further initiative, the TEI (or Text Encoding
Initiative).
Alongside these American-based (but not exclusively American)
initiatives, the compilation of a British-based (but not exclusively
British) 30-million word corpus, the Longman/Lancaster corpus, is
now
available to academic researchers. Two other ambitious British-led
corpus-building initiatives are expected to begin shortly. One is
a
national corpus initiative led by Oxford University Press, with a
number
of collaborators including Oxford and Lancaster Universities,
Longman
Group UK Ltd and the British Library. The aim of
this consortium, like
that of the ACL/DCI, is 100 million words -- a
<page 22>
quantity which seems to have become the 'going rate' for corpora in
the
1990s, just as one million was the rate set by the Brown Corpus
and the
SEU Corpus for the 1960s and 1970s. A second initiative is
that of the
International Corpus of English (ICE), coordinated by
Sidney Greenbaum at
the Survey of English Usage and involving
the compilation of parallel
corpora of English from a wide range of
countries in which English is the
primary first or second language
(see Greenbaum, this volume).
The three British-based corpora mentioned above will all contain
a
combination of written and spoken material. It is generally
acknowledged
now that the overall neglect of machine-readable
spoken transcriptions in
the past is something which must now be
corrected as a matter of the
highest priority. A problem yet to be
thoroughly confronted, however, is
that of how to provide a set of
standards or encoding guidelines for the
transcription of spoken
discourse, so that the needs of various users can
be met (see Chafe
et al., this volume). These range from, at one
end of the scale, the
need of speech scientists to have meticulous spoken
recordings
linked to detailed labellings of phonetic features, to the need
for
lexicographers, for example, to have access to many millions of
words of speech -- which, of necessity, could be only crudely
transcribed.
2.5.2 Corpus tools development
It is widely acknowledged today that a corpus needs the support of a
sophisticated computational environment, providing software tools
both
to retrieve data from the corpus and to process linguistically
the corpus
itself. In spite of the relatively wide availability of some
tools, such
as concordance packages (see Section 2.2.1 above) and --
increasingly --
grammatical tagging systems, most tools exist only in
prototype forms and
in home-grown settings, without adequate
documentation or public
availability.
Some of the tools for which a fairly general need is felt are as
follows.
(a) General-purpose corpus data retrieval tools which go beyond
the
existing concordance facilities, in being able to handle corpora
in
complex formats -- including the non-linear formats of treebanks --
in
being able to sort and search in varied ways, and in being able to
derive
from an (annotated) corpus various kinds of derived data
<page 23>
structures (such as corpus-based frequency lists, lexicons or gram-
mars).
(b) Tools to facilitate corpus annotations at various levels. These
might be used for automatic processing (like current tagging systems),
for semi-automatic interactive use (like the LDB parser at Nijmegen –
see van den Heuvel 1987) or for accelerated manual
analysis and input
(like Garside's skeleton parsing program -- see
Leech and Garside 1991).
Interactive windowing facilities have
much unrealized potential in this
field. One tool for which there is a
strong demand is a robust corpus
parser: something that will be able
to provide a reliable though 'shallow'
parse for large quantities of
text.(25)
(c) Tools to provide interchange of information between corpora
and
lexical and grammatical databases. At the most simplistic level,
a program
which derives lexical frequency lists from raw corpora is a
device for
deriving lexical information from a corpus -- in fact, for
creating or
updating a lexicon. From a tagged corpus, a lemmatized
frequency list may
be derived; and from a treebank, a probabilistic
grammar may be derived
(using observed frequencies of rules as
first-approximation
probabilities). These are examples of how corpora
can create or augment
linguistic databases. From the opposite
direction, a testing algorithm can
use observed corpus data as a
means of evaluating the coverage of a
grammar or the performance
of a parser. From these and similar instances
we can see that
between corpora and linguistic databases or linguistic
models is an
important and rather complex channel of information transfer,
for
which special tools are required.
2.5.3 Development of corpus annotations
As more and more analysis or annotation is carried out on corpora,
it
is natural that annotated corpora themselves provide a platform of
linguistic analysis on which further research can build -- by no means
limited to research undertaken by the original annotators.(26) In this
connection various requirements are beginning to arise with some
urgency.
(a) There is an increasing need for detailed documentation of the
linguistic schemes of analysis embodied in annotations, e.g. tagging
<page 24>
schemes (cf. Johansson <2>et al. <1>1986) and parsing schemes
(cf.
Sampson 1987b).
(b) The devisers of such schemes of analysis generally seek to
incorporate 'consensually approved' features such as (in the simplest
case) traditional parts of speech. But ultimately, there is no such
thing as a consensus analysis: all schemes are likely to be biased in
some way or another -- however minor -- towards a particular
theoretical or descriptive position. For future annotation schemes,
some kind of consultation process, or even a 'popularity poll',
should
be carried out among interested members of the academic
community, to
ensure that the annotations are as far as possible the
most useful for the
greatest number of potential users. In some
cases, alternative annotations
for different communities of users
may be advisable.
(c) At the same time, there is much to be said for a harmonization
of
different annotation schemes. As things are, tagging schemes and
parsing
schemes have arisen piecemeal, and if any standardization
has taken place
it has been no more than the de facto standardization
accorded to a
widely used scheme (such as the Brown Corpus tag-
set). It is widely felt
that standardization of annotation schemes -- in
spite of its attractions
in the abstract -- is too high a goal to aim at;
instead, our goal should
be of annotation 'harmonization' -- using
commonly agreed labels where
possible, and providing readily avail-
able information on the mappings,
or partial mappings, between
one scheme and another. Such a goal should be
easier to attain in a
flexible annotation system allowing for both
hierarchies of annotation
levels and degrees of delicacy in the
specification of categories.
(Spoken corpora may need special tags for
speech-specific items.)
(d) Up to the present, the attention given to different levels of
annotation has been very patchy, as the following rough list attempts
to indicate.