


Next: 4. Using The Toolkit Up: Fast Transformation-Based Learning Toolkit Previous:
2. An Introduction to Contents
Subsections
3.
System Description
The fnTBL system has 2 executables:
- fnTBL-train - that learns the rules that are to be applied
- fnTBL - that applies the rules to the new test data
Both of them
have a set of command line parameters, which will be discussed in the following
subsections, and read also from a parameter file, where some parameters that can
be changed from problem to problem, are specified.
3.1 The
Parameter File
The parameter file is used to store all the parameters that do not change
often during the development of a particular task. We found it to be useful,
because it reduces significantly the number of command-line parameters that need
to be specified, and modifying one parameter does not require the program to be
recompiled (as it would if the parameters would be hard-wired in the program).
Its format is as follows:
where:
- parameter_name represents the name of the parameter
- parameter_value represents the value of the parameter
The
parameter value can also contain previously defined parameters, if they have the
dollar sign 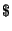 in them. For instance,
in them. For instance, 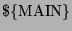 is a legal value if the
variable MAIN was previously defined. I found this to be useful if one wants to
define a main directory, where all the other files reside; when one changes the
location of the main directory, only one line needs to be modified.
is a legal value if the
variable MAIN was previously defined. I found this to be useful if one wants to
define a main directory, where all the other files reside; when one changes the
location of the main directory, only one line needs to be modified.
The following are legal examples of lines in the parameter file:
MAIN =
/remote/bigram/usr/home/rflorian/workdir/research/data/mtbl-toolkit/text_chunking;
FILE_TEMPLATE = ${MAIN}/file.templ;
RULE_TEMPLATES =
${MAIN}/lexical_predicates.richer.templ;
REASONABLE_SPLIT = 10;
REASONABLE_DT_SPLIT = 5;
EMPTY_LINES_ARE_SEPARATORS = 0;
ELIMINATION_THRESHOLD = 0;
The example is actually extracted
from a parameter file associated with the fnTBL POS-tagger. A complete set of
valid parameters are provided in the Appendix. The most important ones are:
- FILE_TEMPLATE - contains the name of the file with the sample feature
names (see 3.2.2);
- RULE_TEMPLATES - contains the name of the file with the rule description
(see 3.2.3);
- CONSTRAINTS_FILE - contains the name of the constraints file (see 3.2.5);
- LOG_FILE - contains the name of a file where all the commands will be
written - useful to keep track what commands were used, if the parameter is
defined;
- EMPTY_LINES_ARE_SEPARATORS - describes if the empty lines are to be
considered separators or not. If the samples are interdependent (e.g. POS
tagging), then the value should be 1 (they are separators). If the samples are
independent, then it should be 0. The reason for its existence is that
sometimes even if the samples are independent, one might want to separate the
samples into sentences (for instance, in lexical POS tagging, Section 5.2)
This section will briefly describe the file formats used with the fnTBL
toolkit. In all the following files, the lines starting with a '#' sign are
considered as comments and, therefore, are ignored.
Both the training file and the test file need to be in a particular format
for the fnTBL tools to work properly. The format requires that each sample be on
a separate line, with the features separated by white space (spaces or tabular
characters). In addition, if the samples are interdependent (like in the POS
tagging case), and organized into ``blocks'' (i.e. sentences), the blocks need
to be separated by a blank line.
Here's an example of such a file:
Revenue NN NN
rose VBD VBD
5 CD CD
% NN NN
to TO TO
$ $ $
282 NN CD
million CD CD
from IN IN
$ $ $
268.3 NN CD
million CD CD
. . .
The DT DT
drop NN NN
in IN IN
earnings NNS NNS
had VBD VBD
been VBN VBN
anticipated VBN
VBN
by IN IN
most JJS JJS
Wall NNP NNP
Street NNP NNP
analysts NNS NNS
, , ,
but CC CC
the DT DT
results NNS NNS
were VBD VBD
reported VBD VBN
after IN IN
the DT DT
market NN NN
closed VBD VBD
. .
.
There are 3 fields for each word (in this case)3.1:
- The word itself (e.g. closed);
- The most likely part-of-speech associated with the word (e.g. VBD);
- The true POS of the word3.2 (e.g. VBN).
As presented in
the Section 2.1,
the system will start to learn transformations that correct the second field to
match, as much as possible, the third field.
Both the training and test data should have this format. Some tools that
compute the most likely tag given the word (for instance) are provided with the
fnTBL distribution and are described in the Appendix section.
3.2.2
FILE_TEMPLATES
The names of the fields associated with the samples are defined in a file
whose name is specified in the parameter file. The name of the parameter is
FILE_TEMPLATES and the file contained in this parameter should have the
following format:
where
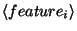 is the name of the
is the name of the 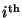 feature associated with the sample;
feature associated with the sample;
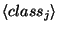 is the name of the
is the name of the 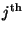 ``guess'' associated with the sample;
``guess'' associated with the sample;
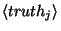 is the name of the
``truth'' associated with the sample; there are the same number of
is the name of the
``truth'' associated with the sample; there are the same number of 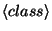 and
and 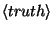 features.
features.
To
make this clearer, here's an example of a template file, taken from POS tagging:
In this example, the feature is word, pos is the name of the
``guess'' of the system at some point in time, and tpos is the name of
the truth. If one wants to perform a simultaneous classification of POS tagging
and text chunking (see [FN01]),
then the corresponding file should be:
where the features are again word, the guesses are named
pos and chunk and the truths (there are 2 classifications in this
case) are named tpos and tchunk.
3.2.3
RULE_TEMPLATES
Because the fnTBL is a general-purpose tool, the user needs to specify the
rule templates - in other words, to describe the kind of rules the system will
try to learn. The description is done by the templates: a template defines which
features are checked when a transformation is proposed. For instance, if one
wants to implement a bigram look-up, then the template consists of the previous
word and the current word.
The predicate of a rule is created as a conjunction of smaller, atomic,
predicates that can be as simple as feature identities; other types verify if
the word ends/begins with a specific suffix/prefix and yet others verify the
identity of one of the previous words. This particular choice of conjunction is
selected for:
- Simplicity - it is easier to represent the rules and templates this way,
both internally and externally (as text);
- Speed-up - the algorithm exploits heavily this choice; if disjunction had
been allowed between atomic predicates, the algorithm would have been a lot
more complicated and no significant speed-up would have been obtained.
A list of atomic predicates' notation is presented after the rule
description.
The format of a rule template is
where:
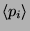 are the atomic
predicates, with
are the atomic
predicates, with 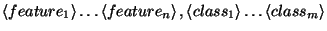 as
arguments
as
arguments
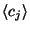 are the classifications
that are to be changed by the rule, and are chosen from
are the classifications
that are to be changed by the rule, and are chosen from 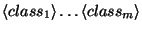
For example
is defining a rule that based on the previous and current word will
change the POS feature, while
will change the POS of a word based on a POS trigram ending on the
current position.
Motivated by some of the problems TBL has been applied to, some types of
atomic predicates have been implemented. Here is the list of how they can be
specified:
- Feature identity:
will check the identity of a particular feature.
- A feature of a neighboring sample (in the case of interdependent samples):
e.g. word_1, pos_-1, chunk_0.
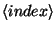 can be negative as well;
there is a restriction that the number has to be an integer belonging to the
range
can be negative as well;
there is a restriction that the number has to be an integer belonging to the
range ![$ \left[ -128,127\right] $](3_ System Description.files/img73.png) ;
;
- A feature that checks the presence of a particular feature in sequence of
samples:
e.g. word:[1,3] checks the presence of the particular word in
the samples on positions +1,+2 or +3, that is:
- A feature checking that one of the features present in an enumeration has
a particular value (useful for independent samples, see the PP attachment case
study):
e.g.
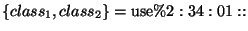 will
return true on a given sample
will
return true on a given sample 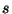 if and only if one of
the features
if and only if one of
the features 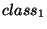 or
or 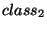 of sample is
of sample is  3.3.
3.3.
One of the big advantages of the
fnTBL toolkit is that the predicate structure is modular, and adding a new
atomic predicate type to the toolkit should not present a big programming
challenge; see the section about the code design for more information.
To make life easier, an additional construction is allowed in the rule file
format - definitions of a rule placeholder:
once a variable is defined, it can be recalled as 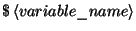 in the rule template
file. This construction helps mostly with ``set'' atomic predicates (the
predicate will return true if any one of a set of features has a given value).
The following is an rule template example taken from the PP-attachment problem:
In here, a predicate-set placeholder is defined -
in the rule template
file. This construction helps mostly with ``set'' atomic predicates (the
predicate will return true if any one of a set of features has a given value).
The following is an rule template example taken from the PP-attachment problem:
In here, a predicate-set placeholder is defined - 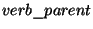 can replace the
predicate
can replace the
predicate 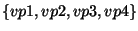 in subsequent rules. The
rule template
in subsequent rules. The
rule template 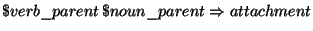 will
try to predict the attachment of a preposition using wordnet parents of the verb
and the first noun of the sample.
will
try to predict the attachment of a preposition using wordnet parents of the verb
and the first noun of the sample.
Both the main programs from the fnTBL toolkit (fnTBL and
fnTBL-learn) use rule files files which list the rules learned by the
system. These rules have meaningful linguistic information in them, and can be
easily read and understood. The format they are presented in is similar to the
one of the template files, rules being actually instantiated templates. The
format is:
where 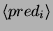 is an atomic predicate,
is an atomic predicate, 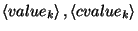 are
valid values for the respective predicates and
are
valid values for the respective predicates and 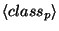 are the classes to be
changed. For instance, again for the POS tagging problem, the rule
will change all the occurrences of infinitive verbs to nouns if the
previous part-of-speech is a determiner; similarly, the rule
will change the attachment from noun to verb if the preposition is
at, in the case of prepositional phrase attachment.
are the classes to be
changed. For instance, again for the POS tagging problem, the rule
will change all the occurrences of infinitive verbs to nouns if the
previous part-of-speech is a determiner; similarly, the rule
will change the attachment from noun to verb if the preposition is
at, in the case of prepositional phrase attachment.
3.2.5 The Constraints File
One less usual parameter for the fnTBL algorithm is the constraints file. The
TBL algorithm suffers from one relatively major problem - since it's output is
not probabilistic, it has no mechanism of estimating the posterior probability
of a class given a sample
and therefore it might assign classes to samples that might not make any
sense at all. For instance, it might assign to the word the the POS tag
VB, which is, of course, very unlikely. Most probabilistic classifiers do
not suffer from this problem, as they have appropriate ways of computing the
posterior probability 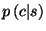 . To avoid this problem,
the TBL algorithm proposed originally by Eric Brill enforced that no new classes
should be assigned to samples: if a sample has been seen in training, then a
rule that would change the classification to a classification that has never
been seen with that particular sample is not allowed to apply.
. To avoid this problem,
the TBL algorithm proposed originally by Eric Brill enforced that no new classes
should be assigned to samples: if a sample has been seen in training, then a
rule that would change the classification to a classification that has never
been seen with that particular sample is not allowed to apply.
We are relaxing here this constraint by allowing the user to specify the set
of allowable associations feature-class for a set of examples, by using
constraint files. If a particular feature is not present in these constraint
files, then a rule that examines that feature can change it as it sees fit.
However, if the feature is present in the file, only rules that change it to
some specified class are allowed to apply to it. This mechanism allows the user
to specify, for instance, that only words which were seen enough times in the
data are not allowed to be associated with new classes.
The format of the constraint file is:
where 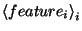 are features on
which the conditioning needs to be done,
are features on
which the conditioning needs to be done, 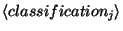 is the classification
that is constrained and
is the classification
that is constrained and
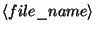 is the file containing the
constraints - a file containing a list of the pairs that need be constrained.
For instance, in the POS tagging example, a constraint in the constraint file
could be
and the file constraint.dat might contain
is the file containing the
constraints - a file containing a list of the pairs that need be constrained.
For instance, in the POS tagging example, a constraint in the constraint file
could be
and the file constraint.dat might contain
saying NN VBG
the DT
their PRP$
them PRP
Any combination of features that does not appear in the constraint
file are not constrained at all, and it's possible for those samples to be
assigned any classification. Also, it is useful to note that the constraints are
stackable; in other words, first a sample is checked against all the constraints
- if it passes, then the class change is performed.
Next: 4. Using The Toolkit Up: Fast Transformation-Based Learning Toolkit Previous:
2. An Introduction to Contents
Radu Florian 2001-09-12 