| Aim: |
| To describe several types of formal grammars for natural language
processing, parse trees, and a number of parsing methods, including a
bottom-up chart parser in some detail. We show the use of Prolog for syntactic parsing of natural language text. Other issues in parsing, including PP attachment, are briefly discussed. |
| Keywords: accepter, active arc, active chart, alphabet (in grammar), ATN, augmented grammar, augmented transition networks, bottom-up parser, CFG, chart, chart parsing, Chomsky hierarchy, constituent, context-free, context-sensitive, CSG, derivation, distinguished non-terminal, generalized phrase structure grammar, generate, GPSG, grammar rule, HDPSG, head-driven phrase structure grammar, language generated by a grammar, left-to-right parsing, lexical category, lexical functional grammar, lexical insertion rule, lexical symbol, lexicon, LFG, Marcus parsing, non-terminal, parse tree, parser, phrasal category, pre-terminal, predictive parser, production, regular, rewriting process, right-linear grammar, right-to-left parsing, robustness, semantic grammar, sentential form, shift-reduce parser, start symbol, systemic grammar, terminal, top-down parser, unrestricted grammar |
| Plan: |
|
- may just give yes/no answer to the question Does this sentence conform to the given grammar: such a parser is termed an accepter
- may also produce a structure description ("parse tree") for correct sentences:
Here is the same tree in list notation ...
(S (NP (NAME John))
(VP (V ate)
(NP (ART the))
(N cat))))
and in a Prolog notation ... s(np(name(john)),
vp(v(ate),
np(art(the),
n(cat))))
| 1. S -> NP VP 2. VP-> V NP 3. NP-> NAME 4. NP-> ART N | grammar rules |
| . | . |
| 5. NAME -> John 6. V -> ate 7. ART -> the 8. N -> cat | lexical entries |
T = { ate, cat, John, the}
N = { S, NP, VP, N, V, NAME, ART}
P = { S -> NP VP, VP-> V NP, NP-> NAME, NP-> ART N, NAME-> John V-> ate, ART-> the, N-> cat} .
Notice how the productions were split into grammar rules and lexicon above. N, V, NAME and ART are called pre-terminal or lexical symbols.
Aside: In programming language grammars, there would be context-free rules like:
WhileStatement -> while Condition do StatementList
end
StatementList ->
Statement
StatementList -> Statement ;
StatementList
To derive a sentence from a grammar, start with the start symbol S, and refer to it as the current string. Repeatedly perform the following rewriting process:
| Current string | Rewriting | |
|---|---|---|
| S | => NP VP |
|
| => NAME VP |
|
|
| => John VP |
|
|
| => John V NP |
|
|
| => John ate NP |
|
|
| => John ate ART N |
|
|
| => John ate the N |
|
|
| => John ate the cat |
|
Parsing might be the reverse of this process (doing the steps shown above in reverse would constitute a bottom-up right-to-left parse of John ate the cat.)
Use this grammar:
S -> NP VP
NP -> ART N | NAME
PP -> PREP NP
VP -> V | V
NP | V NP PP | V PP
Sentence: 1 The 2 dogs 3 cried. 4
Backup states Position
S -> NP VP 1
-> ART N VP 1
NAME VP 1
-> (The) N VP 2
NAME VP 1
-> (dogs) VP 3
NAME VP 1
-> V 3
V NP 3
V NP PP 3
V PP 3
NAME VP 1
-> (cried.) 4
| The dogs cried | -> ART N V |
| -> NP V | |
| -> NP VP | |
| -> S |
| Indication of parsing state | Comment |
|---|---|
| The horse raced past the barn ... | "past the barn" parsed as PP, "raced" parsed as [main] verb |
| The horse raced past the barn fell | oops! |
| The horse ... | backtrack to this point and start over |
| The horse raced past the barn fell | "past the barn" parsed as PP again: "raced" parsed as ADJ [from past participle] starting the ADJP ["raced past the barn"] | >
The chart is a record of all the substructures (like past the barn) that have ever been built during the parse. A chart is sometimes also called a well-formed substring table. Actual charts get complex rapidly.
Charts help with "elliptical" sentences:
1: Q. How much are apples?
2: A. Thirty cents each.
3:
Q. Plums?
An attempt to parse 3 as a sentence fails, but all is not lost, as the analysis of plums as an NP is on the chart. Successful parsing of the entire utterance as any kind of structure can be useful.
This algorithm expresses an efficient bottom-up parsing process. It is guaranteed to parse a sentence of length N within N*N*N parsing steps, and it will perform better than this (N*N steps or N steps) with well-behaved grammars.
The algorithm constructs (phrasal or lexical) constituents of a sentence. We shall use the sentence the green fly flies as an example in describing a NL-oriented parser similar to Earley's algorithm. The sentence is notionally annotated with positions: our sentence becomes 0the1green2fly3flies4.
In terms of this notation, the parsing process succeeds if an S (sentence) constituent is found covering positions 0 to 4.
Points (1) to (8) below do not completely specify the order in which parsing steps are carried out: one reasonable order is to scan a word (as in (2)) and then perform all possible parsing steps as specified in (3) - (6) before scanning another word. Parsing is completed when the last word has been read and all possible subsequent parsing steps have been performed.
Parser inputs: sentence, lexicon, grammar.
Parser operations:
(0) The algorithm operates on two data structures: the active chart - a collection of active arcs (see (3) below) and the constituents (see (2) and (5)). Both are initially empty.
(1) The grammar is considered to include lexical insertion rules: for example, if fly is a word in the lexicon/vocabulary being used, and if its lexical entry includes the fact that fly may be a N or a V, then rules of the form N -> fly and V -> fly are considered to be part of the grammar.
(2) As a word (like fly) is scanned, constituents corresponding to its lexical categories are created:
N1: N -> fly FROM 2 TO 3, and
V1: V -> fly FROM 2 TO 3
(3) If the grammar contains a rule like NP -> ART ADJ N, and a constituent like ART1: ART -> the FROM m TO n has been found, then an active arc ARC1: NP -> ART1 * ADJ N FROM m TO n
is added to the active chart. (In our example sentence, m would be 0 and n would be 1.) The "*" in an active arc marks the boundary between found constituents and constituents not (yet) found.
(4) Advancing the "*": If the active chart has an active arc like:
ARC1: NP -> ART1 * ADJ N FROM m TO n
and there is a constituent in the chart of type ADJ (i.e. the first item after the *), say
ADJ1: ADJ -> green FROM n TO p
such that the FROM position in the constituent matches the TO position in the active arc, then the "*" can be advanced, creating a new active arc:
ARC2: NP -> ART1 ADJ1 * N FROM m TO p.

(5) If the process of advancing the "*" creates an active arc whose "*" is at the far right hand side of the rule: e.g.
ARC3: NP -> ART1 ADJ1 N1 * FROM 0 TO 3
then this arc is converted to a constituent.
NP1: NP -> ART1 ADJ1 N1 FROM 0 TO 3.
Not all active arcs are ever completed in this sense.
(6) Both lexical and phrasal constituents can be used in steps 3 and 4: e.g. if the grammar contains a rule S -> NP VP, then as soon as the constituent NP1 discussed in step 5 is created, it will be possible to make a new active arc
ARC4: S -> NP1 * VP FROM 0 TO 3
(7) When subsequent constituents are created, they would have names like NP2, NP3, ..., ADJ2, ADJ3, ... and so on.
(8) The aim of parsing is to get phrasal constituents (normally of type S) whose FROM is 0 and whose TO is the length of the sentence. There may be several such constituents.
Grammar:
1. S -> NP VP
2. NP -> ART ADJ N
3. NP -> ART N
4. NP ->
ADJ N
5. VP -> AUX V NP
6. VP -> V NP
Sentence: 0 The 1 large 2 can 3 can 4 hold 5 the 6 water 7
Lexicon:
the... ART
large... ADJ
can... AUX, N, V
hold... N, V
water... N,
V
Steps in Parsing:
*sentence*: the *position*: 1 *constituents*: ART1: ART -> "the" from 0 to 1 *active-arcs*: ARC1: NP -> ART1 * ADJ N from 0 to 1 [rule 2] ARC2: NP -> ART1 * N from 0 to 1 [rule 3] *sentence*: the large *position*: 2 *constituents*: add ADJ1: ADJ -> "large" from 1 to 2 *active-arcs*: add ARC3: NP -> ART1 ADJ1 * N from 0 to 2 [arc1*->] ARC4: NP -> ADJ1 * N from 1 to 2 [rule 4] *sentence*: the large can *position*: 3 *constituents*: add NP2: NP -> ART1 ADJ1 N1 from 0 to 3 [arc3*->] NP1: NP -> ADJ1 N1 from 1 to 3 [arc4*->] N1: N -> "can" from 2 to 3 AUX1: AUX -> "can" from 2 to 3 V1: V -> "can" from 2 to 3 *active-arcs*: add ARC5: VP -> V1 * NP from 2 to 3 [rule 6] ARC6: VP -> AUX1 * V NP from 2 to 3 [rule 5] ARC7: S -> NP1 * VP from 1 to 3 [rule 1] ARC8: S -> NP2 * VP from 0 to 3 [rule 1] *sentence*: the large can can *position*: 4 *constituents*: add N2: N -> "can" from 3 to 4 AUX2: AUX -> "can" from 3 to 4 V2: V -> "can" from 3 to 4 *active-arcs*: add ARC9: VP -> AUX1 V2 * NP from 2 to 4 [arc6*->] ARC10: VP -> V2 * NP from 3 to 4 [rule 6] ARC11: VP -> AUX2 * V NP from 3 to 4 [rule 5] *sentence*: the large can can hold *position*: 5 *constituents*: add N3: N -> "hold" from 4 to 5 V3: V -> "hold" from 4 to 5 *active-arcs*: add ARC12: VP -> AUX2 V3 * NP from 3 to 5 [arc11*->] ARC13: VP -> V3 * NP from 4 to 5 [rule 6] *sentence*: the large can can hold the *position*: 6 *constituents*: add ART2: ART -> "the" from 5 to 6 *active-arcs*: add ARC14: NP -> ART2 * ADJ N from 5 to 6 [rule 2] ARC15: NP -> ART2 * N from 5 to 6 [rule 3] *sentence*: the large can can hold the water *position*: 7 *constituents*: add S2: S -> NP1 VP2 from 1 to 7 [arc7*->] S1: S -> NP2 VP2 from 0 to 7 [arc8*->] VP2: VP -> AUX2 V3 NP3 from 3 to 7 [arc12*->] VP1: VP -> V3 NP3 from 4 to 7 [arc13*->] NP3: NP -> ART2 N4 from 5 to 7 [arc15*->] N4: N -> "water" from 6 to 7 V4: V -> "water" from 6 to 7 *active-arcs*: add ARC16: VP -> V4 * NP from 6 to 7 [rule 6] ARC17: S -> NP3 * VP from 5 to 7 [rule 1]Doing the same steps diagrammatically:
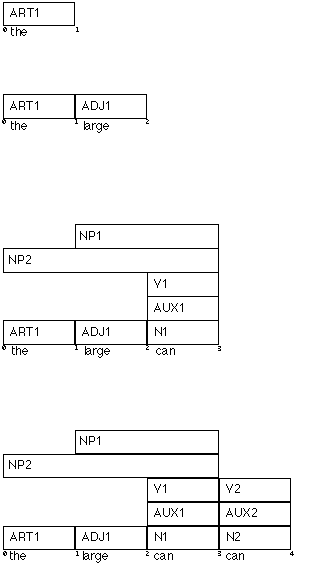
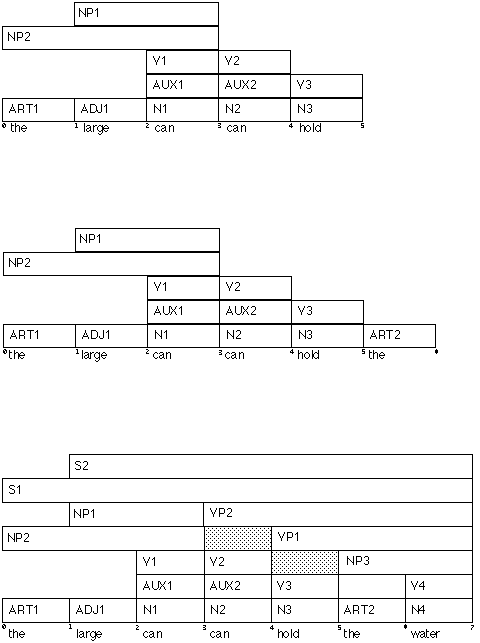
. . . . . . .
A frame-like, or slot/filler representation is suitable: Jack found a dollar
(S SUBJ (NP NAME "Jack") MAIN-V find TENSE past OBJ (NP ART a HEAD dollar)) s(subj(np(name(jack))), mainv(find), tense(past), obj(np(art(a), head(dollar))))
Grammar rules can be encoded directly in Prolog:
| S -> NP VP | ..... | s(P1,P3) :- np(P1,P2), vp(P2,P3). |
That is, there is an S from position P1 to position P3 if there is an NP from P1 to P2 and a VP from P2 to P3. Similarly:
| VP-> V NP | ..... | vp(P1,P3) :- v(P1,P2), np(P2,P3). |
| NP-> NAME | ..... | np(P1,P2) :- propernoun(P1,P2). |
| NP-> ART N | ..... | np(P1,P3) :- art(P1,P2), noun(P2,P3). |
| NAME -> John | ..... | isname(john). |
| V -> ate | ..... | isverb(ate). |
| ART -> the | ..... | isart(the). |
| N -> cat | ..... | isnoun(cat). |
noun(From, To) :- word(Word, From, To), isnoun(Word).
v(From,
To) :- word(Word, From, To), isverb(Word).
propernoun(From, To) :-
word(Word, From, To), isname(Word).
To use the system as so far described, one can assert the words in their sentence positions:
word(john, 1, 2).
word(ate, 2, 3).
word(the, 3, 4).
word(cat, 4,
5).
and then use the Prolog query s(1,5)? This will result in ** yes.
To get at the structure of the sentence, add extra arguments to pass the structure across necks as it is built:
s(P1,P3,s(NP,VP)) :- np(P1,P2,NP),
vp(P2,P3,VP).
vp(P1,P3,vp(v(Verb),NP)) :- v(P1,P2,Verb),
np(P2,P3,NP).
np(P1,P2,np(name(Name))) :-
proper(P1,P2,Name).
np(P1,P3,np(art(Art),noun(Noun)))
:-
art(P1,P2,Art),
noun(P2,P3,Noun).
art(From, To, Word) :- word(Word, From, To), isart(Word).
noun(From, To,
Word) :- word(Word, From, To), isnoun(Word).
v(From, To, Word) :- word(Word,
From, To), isverb(Word).
proper(From, To, Word) :- word(Word, From, To),
isname(Word).
See http://www.cse.unsw.edu.au/~cs9414/notes/nlp/dcg2.pl for a full version of this program.
The boy saw the man on the hill with the telescope
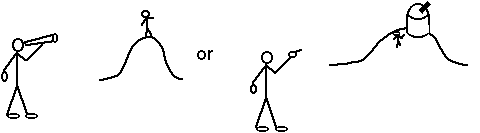
The two visual interpretations correspond to two different parses (coming from different grammar rules (VP -> V NP PP and NP -> NP PP):
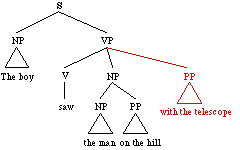
| or | 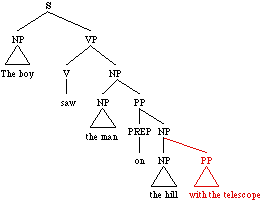 |
Limitations of Syntax in NLP
| Summary: Grammars and Parsing |
| There are many approaches to parsing and many grammatical formalisms. Some problems in deciding the structure of a sentence turn out to be undecidable at the syntactic level. We have concentrated on a bottom-up chart parser based on a context-free grammar. We will subsequently extend this parser to augmented grammars. |
CRICOS Provider Code No. 00098G