| Recall that one of the issues that has engaged the interest of cognitive scientists is whether human sentence understanding is a deterministic or nondeterministic process. That is, as we process an incoming sentence do we always or almost always make the choices that will result in the correct interpretation? Or do we consider possible interpretations that turn out to be incorrect? | ||
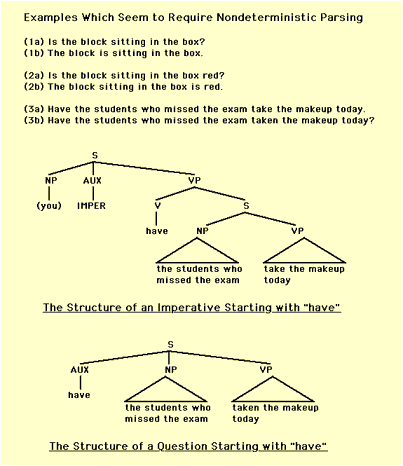 |
The figure to the left provides examples that might be interpreted as requiring that we consider possible interpretations that turn out to be incorrect....that we use a method of parsing that is nondeterministic. In the first two examples, the surface form of the sentence (whether it begins with 'Is' or 'The') provides reliable information on which to correctly guess that the (a) sentences are to be interpreted as question sentences and the (b) sentences as declarative sentences. But note that in the third pair of sentences it is not until the eighth word that the input provides information on which to choose the correct interpretation. Below this third example pair is shown a representation of the way these two sentences are structured. Note that either one must develop:
It is some work that considers this last choice that we will consider here. | |
| One kind of parsing strategy that had been studied in work on parsing formal languages is a parser that is referred to as a look-ahead parser. A look-ahead parser is one that when deciding how to interpret input symbol i is allowed to look at the next k input items before making its decision. | ||
 |
In his dissertation research, M. Marcus set about the task of attempting to construct a parser for natural language that parsed sentences deterministically. The figure to the left is adapted from Marcus' research. At the top of this figure is his statement of the determinism hypothesis. Recall the various exhaustive search methods that were considered in the section on computational approaches to the study of cognition (Exhaustive Search Methods). Since these exhaustive methods may consider all of the possible hypothesis, it is obvious that both the method of breadth-first search and the method of depth-first search are nondeterministic methods. But notice they realize the nondeterminism in differing ways. In breadth-first search each alternative is explicitly represented and maintained until a solution is found. In depth-first search back-tracking is used when one alternative is abandoned and another is explicitly considered. In the center of this figure, Marcus enumerates various ways in which nondeterminism might be realized in an algorithm without explicitly maintaining the alternatives. Finally, at the bottom the the figure are listed the properties that Marcus hypothesized as sufficient to realize a deterministic parser of English. And the figure below, provides a schematic picture of the structure of his parser. | |
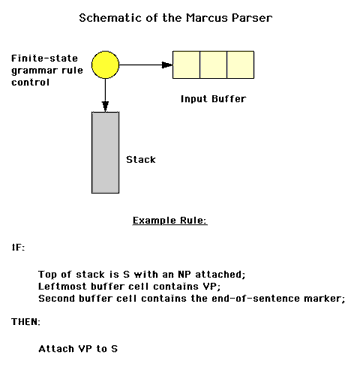 |
Consider the first property; namely, that the parser be Partially Data Driven. The data that supports this claim is exemplified by sentences (1a) and (1b). A strictly top-down parse would consider many possible parses. But the first word of each of these sentence can be used to immediately limit the hypotheses considered. But the parser must also Reflect Expectations. This is a characteristic of top-down parsing and the assumption here is that human sentence understanding is both responsive to the implications of the current input data, but also predictive. Sentences (2a) and (2b) provide an example of the type of data that support this assumption. In (2a) a noun phrase is expected whereas in (2b) a sentence is expected. Finally, in order to correctly handle sentences such as (3a) and (3b) it is assumed that there is a capacity for Constrained Look-Ahead. Note, because the capacity for look-ahead is constrained to some limit, k, if the parsing of some sentence exceeds this bound, we would expect the parser to break down and be unable to deterministically construct a parse of the sentence. In the figure to the left, the Stack is the structure that contains the subproblems introduced during the parse. This stack provides the basis for implementing the predictive property of the parser. | |
|
The Input Buffer provides the structure that is required to realize the Look-Ahead property of the parser. Beneath this diagram is an example rule. Notice that the If portion of the rule makes reference both to the Stack (the predictive aspect of the parsing process) and to the Input Buffer (the data-driven aspect of the parsing process). Is this then a correct model of human sentence understanding? Perhaps not, but it illustrates the way in which our ability to construct computational artifacts that attempt to realize human competence and performance in some domain (in this case sentence parsing) extends our ability to imagine and attempt to empirically test the various possible ways our minds might work. | ||
|
| ||
Understanding, Interpreting and Remembering Events |
||
| © Charles F. Schmidt | ||