t-test for One Sample
Why is this Important?
Some times you have to decide if a sample mean is different from a
hypothesized population mean. You have calculated mean value and standard
deviation for the group assuming you have measurement data. For example:
- You hear that the average person sleeps 8 hours a day. You think college
students sleep less. You ask 10 college kids how long they sleep on an average
day.
- You get the data and the mean of sleep time is 6.5 hours.
- Is this luck? Did you happen to pick a group of light sleepers by chance?
Or do college kids really sleep less?
- What you are asking is whether college kids come from a population
separate from the rest of society. "Society" supposedly being all the people
who contributed to the mean of 8 hours a night that we hear
about.
The Big Idea: Does Your Group Come from a Different Population
than the One Specified?
The problem is that if you calculate a sample mean and it is physically
different from the one hypothesized, there are two
possible reasons for the difference:
- Your sample comes from a different
population and the sample mean represents a different population
mean. When this happens, you reject the Null
Hypothesis.
- The group comes from the same population and the
mean varies by chance. You just happened to pick a sample group
with a mean that misrepresents the population it came from. The group isn't
really different. When this happens you fail to reject the
Null Hypothesis - see the graphic on the next page.
The way to decide which is the case is with the one
sample t-test. You will compare the sample mean to the population
mean and get an estimate of the probability that the sample mean is different by
chance. How does the t-test work?
First, you will calculate the mean and standard deviation for your
group. A computer might actually do all of this for you.
Let me introduce some notation. The sample mean is usually noted as ` X . The population mean
is noted as m. You are
testing to see whether or not ` X is different from
m.
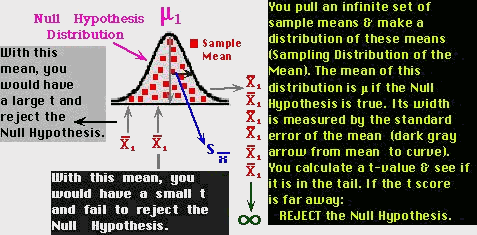
Next:
- You will use the t-test formula to compute the
t-value.
- The t-score is like a z-score and tells you if the sample mean is far away from the population
mean (m). You will use the sampling distribution of the mean
to do this.
- If the t-value is big enough (you look
it up in a t-table), you will reject the Null
Hypothesis and say you have a
difference. If it is not big enough you will say that you have not
found a difference and fail to reject the Null Hypothesis.
How does the t ratio do this?: 
- The t-test sets up a sampling distribution of means with a
mean that is specified by the null hypothesis (m).
- The t-test calculates if your sample mean is far in the tails
of the sampling distribution and far away from the population mean
(m).
- Thus, the difference may be too big to be chance. If your
group was really from the null hypothesis distribution, then the difference
should be close to zero.
- The t-score is made
a relative score by dividing the difference between the sample mean and
m by the standard error of
the mean. See your book for the standard error formula.
- That's how we know if your sample mean is rare by chance as
we can calculate the areas in the tales (see the z-score workshop).
