|
ELL230: COMPUTATIONAL LINGUISTICS II Lecture 2 Topics covered so far Theory
Practice
Theory A general parsing algorithm The mechanism inside the transducer has to take the strings of a language as input and deliver the corresponding structural descriptions as output: it implements a parsing algorithm. In this lecture we look at a general parsing algorithm. Given a string generated by a grammar, the task of finding its derivation according to that grammar is called parsing, as we have seen. Note the implication: to build a parser for a language, the grammar which generates the language has to be known. There are two general strategies for parsing:
We will not be going into bottom-up parsing; the rest of this section explains what the above rather general account of top-down parsing means.
Top-down parsing Earlier, we looked at derivation of a string using a grammar. It was noted that the process of generating a string using a phrase structure grammar is the successive rewriting of sentential forms using the productions of the grammar, starting with the sentential form S. The sequence of sentential forms required to generate a string constitutes the derivation of the string according to the grammar. In other words, a derivation is a finite sequence of sentential forms of which the first is the string symbol S, and in which each subsequent sentential form is obtained by copying the current sentential form and rewriting the leftmost nonterminal symbol in accordance with one of the productions of the grammar. The rewriting process terminates when the sentential form contains no more nonterminal symbols, but consists entirely of terminals (that is, symbols of the alphabet of the language). Now, it should be clear that the choice of which production to apply at any given step of the derivation, and the order of such choices, is what gives the string being generated its structure. This structure is usually represented as a derivation tree, otherwise known as a phrase marker. This tree is built as the derivation proceeds. We start with a tree containing only one node, the root node S. For each step in the derivation, the tree is correspondingly extended. That is, every time a production is used to replace a nonterminal in the current sentential form by the symbol(s) on the right-hand side of the production, lines are drawn from the corresponding nonterminal in the existing tree to each symbol in the replacement string. Take as an example a fragment of a CFG:
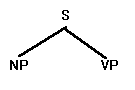
A derivation starts with S, so the initial tree is: S At the next step S has to be rewritten. The grammar offers only one possibility: NP VP. The tree now looks like this:
At the next step NP has to be rewritten: the sentential form now is DET N VP. After several more steps expanding the NP, the tree looks like this:
The derivation, and the simultaneous construction of the tree, proceeds in this way until a string is generated, at which point the structure tree is complete as well. What I'm leading up to is the basic insight that every string generated by a grammar has a structure associated with it. Parsing tries to rediscover that structure. The question is: how does one go about it? We begin with a very general, but also very inefficient, method. It is presented here because it is a good introduction to parsing algorithms. This very general method simply tries out all the possibilities. Let's say we are given a CFG and a target string, that is, a string to be parsed. The object is to discover the derivation of the string --the sequence of production applications which started at S and ended up with the string. In the light of the foregoing discussion, this amounts to finding the derivation tree for the string. That being so, one builds a tree of all possible derivations, and picks out the one that leads to the target string. The algorithm is: 1. Start at S 2. At each step:
3. Repeat 2 until the target string has been generated, at which point its structure will have been discovered.
An example should clarify this. Consider the following CFG for a small fragment of English:
The target string is: the man in the house cried. We want to discover the derivation of this target string from the CFG.
Begin construction of the parse tree: S There is only one possible derivation from S. Insert the subtrees concerned into the parse tree:
Examine the possibilities NP and VP to see if either of them can be eliminated. Neither can. There are two possible derivations from NP. Insert them into the tree.
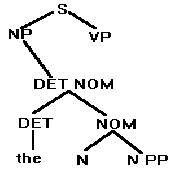
Examine the possibilities to see if any of them can be eliminated. The leftmost NOM can because, according to the grammar, NOM can ultimately generate a noun or a noun followed by a prepositional phrase, which means that the string would have to begin with a noun. But it doesn't. It begins with a determiner. Therefore discontinue the leftmost NOM, that is, don't develop its possibilities any further. There is only one possible derivation from DET. Insert it into the tree:
There are two possible derivations from NOM. Insert them:
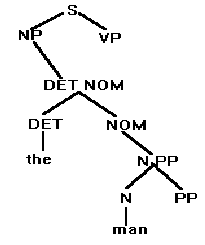
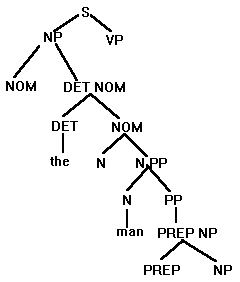
Examine the possibilities to see if any can be eliminated. The leftmost N can: it generates a noun, and the next word in the target string is a noun, but it cannot generate a following prepositional phrase, which the target string has. Do not develop the leftmost N any further. There is only one possible derivation from the rightmost N: a noun. Check the possible expansions of N in the grammar, select the appropriate noun, and insert it into the tree:
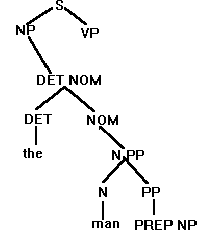
There is only one possibility from PP. Insert it:
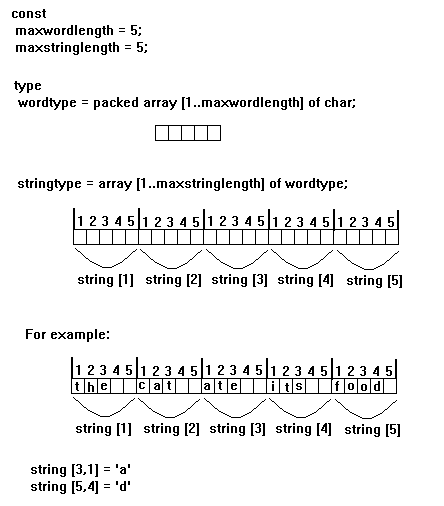
And so on; the algorithm will eventually generate the target string, and will thereby have discovered the target string's structure. This very general algorithm is reliable, in the sense that it will either eventually discover the correct structure, or fail to and thus pronounce the string illegal relative the the grammar, that is, exclude the string from the language which the grammar generates. It is, however, also inefficient. The above grammar is very small. Any useful grammar for a natural language will be very much larger. For such a large grammar, exhaustive checking of possibilities becomes a major undertaking. This is because the number of possibilities to be checked increases very rapidly relative to increase in grammar size. As a result, this algorithm is useless for real-time natural language processing systems on account of the demands which they make on computational resources, and their consequent slowness. Something more efficient is needed. Practice Review of representation of natural language strings in Pascal So far, the languages we have dealt with have consisted of strings made up of single letters. In natural languages, however, the strings (ie, sentences) are made of words, which are themselves strings of letters. It is therefore necessary to find some way of representing word strings in Pascal. The approach is to represent words are arrays of letters, and to represent strings as arrays of words, so that a natural language string becomes and array of arrays.
Assignment None this week. If you haven't done the last exercize, make sure you do this week.
|
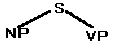
 .
.