English and other natural languages are not built this way. In a natural language the context in which a word is used may change the meaning of the word. As a matter of fact, even programming languages such as C++ are not completely context-free. If you use the string "<<" in a C++ program and there is an ostream to its left, then this string is the insertion operator. But if "<<" has an integer to its left, then it is the bitwise left-shift operator.
For each class of languages prior to the recursive languages we saw both an acceptor (a machine) and a generator (a regular expression or a grammar.) But for the recursive and recursively enumerable languages we have seen only the acceptors. We shall now study grammars for languages accepted by Turing machines, beginning with grammars for the r.e. languages.
The grammars we study in this chaper are called phrase-structure grammars. A phrase-structure gramar is defined as follows:
SHere is a derivation made from this grammar. At each step the set of symbols that gets replaced in the next step is underlined.XS |
X
SNotice that using the rule aaaXXS
Note that a context-free grammar is a phrase-structure grammar. You can see this if you review the restrictions on phrase-structure grammars. So languages that can be generated by context-free grammars are a subset of languages that can be generated by phrase-structure grammars.
Recall that the language {anbnan | n > 0} is not a context-free language. We can generate this language with a phrase-structure grammar:
SHere are some derivations using this grammar, first a derivation of aba and then a derivation of aabbaa.
SWe use the S rules to build up the leftmost group of a's in our working string, using the rule S
It is possible to "get stuck" during a derivation with a PSG by using rules in an order that leads nowhere. For example, consider what happens if we do not shuffle the A's and B's before we change them to little letters.
SNow we're stuck. We can draw a total language tree for a phrase-structure grammar but some branches will end with working strings that cannot be used to derive any words. In the tree for the above grammar, one branch will end with the working string aabaBA.
Here is an interesting theorem.
Theorem. Given a PSG for language L, there is another PSG for L which has the same alphabet of terminals and whose rules are all of the form
string of nonterminalswhere the left side cannot be
Proof. We give an algorithm for changing any PSG into a PSG meeting the restriction that the left-hand-sides of its rules contain only nonterminals. Make up a new nonterminal for each terminal and add one rule for each, rules such as
N1Then change all occurrences of each terminal into the nonterminal corresponding to that terminal. QED
The first grammar below is changed into the second by this algorithm:
SA grammar of the form just described, in which each rule's left-hand-side is a string of only nonterminals, is called type 0 (type zero.) Because of the previous theorem we know that the phrase-structure grammars and the type 0 grammars are equivalent. Type 0 is one of the four classes of grammars that Noam Chomsky defined in 1959. The table below summarizes Chomsky's Hierarchy:
| Type | Name | Restrictions on Rules X |
Acceptor |
| 0 | Phrase-structure = Recursively Enumerable |
X = string of nonterminals Y = any string |
TM |
| 1 | Context-sensitive | X = string of nonterminals Y = any string with length at least the length of X |
LBA (linear-bounded automaton, which is a TM with bounded tape) |
| 2 | Context-free | X = one nonterminal Y = any string |
PDA |
| 3 | Regular | X = one nonterminal Y = tN or Y = t, where t is a terminal and N is a nonterminal |
FA |
Chomsky's descriptions of language classes match nicely with some of the ones we have studied. We have completely described types 2 and 3, although Chomsky did not subdivide his type 2 languages into deterministic and nondeterministic the way we did. Type 1 is a class that computer theorists don't work with very often, but we suspect that natural languages fall into this category. Note that the type 1 category does not correspond exactly to the class of recursive languages, but is a subclass of those languages. In other words, type 1 languages are recursive but not all recursive languages are type 1 languages. We can look at the rules of a grammar and determine that the grammar generates a context-sensitive (type 1) language, but it is impossible to look at the rules of a grammar and tell that the grammar generates a recursive language.
Here is our more detailed hierarchy of languages.
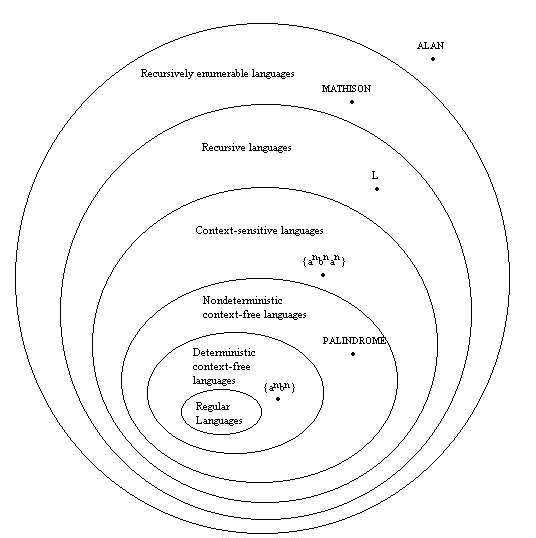
No two of these classes are the same. We have placed a language in each class that is not a member of any of that class's subclasses. Note that the language L in the class of recursive languages is defined by our author in this chapter, but we will not discuss it. Suffice it to say that there are languages (like L) that are recursive but not context-sensitive.
Theorem. Given L1 and L2, two r.e. languages, the language L1L2 is also r.e. In other words, the set of r.e. languages is closed under concatenation.
Proof. The proof we used to show that the set of context-free languages is closed under concatenation almost works here, except that we need to subscript both the terminals and the nonterminals in each of our original grammars to keep from mixing up the rules of the different grammars. Refer back to that proof in chapter 17. QED
Example: Consider the language LL where language L is defined by this grammar:
SNote that the only string that this grammar can produce is the string a, so the only string that we should produce by concatenating the languages is the string aa. We create two copies of this grammar, one subscripted with 1 and the other with 2. Think what would happen if we only subscripted the nonterminals of the grammars. We could do this derivation:
STo avoid such mistakes, we subscript both terminals and nonterminals, as follows:
S1Now we build a new grammar by introducing a new nonterminal S and the rule S
S
Theorem. If L is an r.e. language, then L* is also r.e. The set of recursively enumerable languages is closed under Kleene star.
Proof. Here we have to be careful not to allow strings of terminals from one occurrence of a word in L to attach themselves to a part of the derivation from another word in L, and possibly produce a word not in L*. We need to make two copies of our grammar, one subscripted with a 1 and one subscripted with a 2, then alternate between these grammars when producing strings in L*. We then add the rules
SWe need to subscript both terminals and nonterminals as we did in the previous proof. QED
We have finished our study of languages for this semester. Here is a table to summarize our findings.
| Type of Language | Language Defined By | Corresponding Acceptor | Does Nondeterminism Give More Power? |
Set Is Closed Under |
| regular language | regular expression | finite automaton, transition graph | no | union, concatenation, Kleene star, intersection, complement |
| context-free language | context-free grammar | pushdown automaton | yes | concatenation, Kleene star, union |
| recursive language | phrase-structure grammar | Turing machine that never loops |
no | concatenation, Kleene star, union, intersection, complement |
| recursively enumerable language | phrase-structure grammar | Turing machine | no | concatenation, Kleene star, union, intersection |